LANGUAGE IN INDIA
Strength for Today and Bright Hope for Tomorrow
2 : 1 March 2002
Editor: M. S. Thirumalai, Ph.D.
Associate Editor: B. Mallikarjun, Ph.D.
Ph.D. Dissertation
Transformation of Natural Language into Indexing Language: Kannada - A Case Study
B. A. Sharada, Ph.D.
© 2002. by B. A. Sharada, E-mail: drsharada@sancharnet.in, or sharada@ciil.stpmy.soft.net . Ph.D. in Library and Information Science, Awarded by the University of Mysore, 1999. Guide: Dr. M. A. Gopinath, E-mail: gopinath@nccu.edu, Visiting Professor, School of Library and Information Sciences, North Carolina Central University, Fayetville Road, Durham NC 27707, USA, and formerly Professor and Head, Documentation Research and Training Centre, Bangalore-560 059, India. (Kindly note that the appendices chapter is not included in this presentation for technical reasons. Our scanner is not sensitive enough to make clear copies of the Kannada typewritten materials and black and white diagrams as images. For copies of the appendices, please e-mail Dr. Sharada. Editor, Language in India.)
CONTENTS
| Introduction | |
| Chapter One | Index and Indexing Language |
| Chapter Two | Theories of Linguistics |
| Chapter Three | Compatibility - Linguistics and Indexing Language |
| Chapter Four | Properties of Kannada |
| Chapter Five | Technical Literature and Glossary in Kannada |
| Chapter Six | Rules for Generating Subject Headings- Pre - coordinate Indexing |
| Chapter Seven | Transformational Grammar and Analysis of Document Titles in Kannada |
| Chapter Eight | Illustrative Examples in Demonstrating Rules |
| Chapter Nine | CONCLUSION |
| References |
*** *** ***
INTRODUCTION
0. Introduction
There is a dramatic increase in the quantum of knowledge and information resulting in increase in the production of books and other multimedia communication materials including Compact Discs - Read Only Memory (CD-ROM). These repositories of knowledge are the bridges between information generators and the information users . The success of such a repository is completely dependent upon how tactfully the recorded knowledge is well organized and retrieved.
Classification and indexing is an efficient method of organizing materials subject wise. Such an arrangement is most useful for effective retrieval of the kind of information required by the patrons and the information scientists serving them. As an aid to this work there are so many systematic indexing languages like Dewey Decimal Classification, Universal Decimal Classification etc. The significant contribution from India to this field is Colon Classification developed by Dr.S.R.Ranganathan (SRR).
0.1. Need and Importance of the Study
An Indexing Language (IL) is a technical language based on the structure and functioning of a Natural Language (NL). Development of an IL in a NL is part of the development of a NL. Most of the existing and available ILs are rendered or based upon English. Many ILs are also available in some other languages like French, German, Chinese, Italian etc.
Though India is rich with 1652 mother tongues, out of which 18 are Scheduled Languages included in the Constitution of India, there is a paucity in development of ILs in Indian languages. It is ideal that every language has its own IL and at least a family of languages have an IL.
Karnataka, one of the States of the Union of India was formed on linguistic basis on Novembwr 1, 1956. The Karnataka Official Language Act 1963 recognized Kannada as its Official language. This gave a fillip for the extensive use of it in administration, education and mass communication. The Government, voluntary organizations, institutions and universities are making all round efforts to develop it as an effective medium of communication for all the purposes. However, for want of adequate and appropriate research in Indian languages in the area of IL, libraries and information centers are adopting English coinage as they are without any alternatives or modified formulation to meet the linguistic and cultural needs.
The structure of Indian languages in general is different from that of English. Hence, they need an IL , each derived on the basis of their structure. Since India is a multilingual country and is considered as a linguistic area , the comprehensive rules derived in developing an IL in Kannada can be applied to other Dravidian languages and also to all other Indian languages. This study of preparation of a module has utilitarian value to prepare the pre-coordinate IL in Kannada in particular and other Indian languages in general.
The glossary had to be prepared , since there is no authority or subject heading list in Kannada like Library of Congress Subject Headings (LCSH) and the Sears List of Subject Headings in English.
0.2. Definition of the Concepts
The following are the operational definitions of some of the important technical terms used in the study.
Natural Language: The NL is the primary medium for human communication . Function of a NL is to communicate semantic content of its expression directly.
Indexing Language: The IL is an artificial language made up of expressions connecting several kernel terms. The function of an IL is to take whatever a NL does and in addition organize the semantic content through a different expression providing a point of access to the seekers of information. An IL is a system for naming subjects and has controlled vocabulary. The vocabulary of an IL may be verbal or coded. A classification scheme uses coded vocabulary in the form of notation and authority lists uses verbal vocabulary.
Kannada: Kannada is one of the 1652 mother tongues spoken in India. Forty three million people use it as their mother tongue. It is also one of the 18 Scheduled Languages included in the VIII Schedule of the Constitution of India. It belongs to the Dravidian family of languages. Within Dravidian, it belongs to the South Dravidian group. It is recognized as the Official Language of Karnataka.
Interdisciplinary Subject: A subject that emerges as a result of interaction between two known, well demarcated disciplines.
Infolinguistics: An interdisciplinary subject that has emerged out of the interaction between the two subjects - information science and linguistics.
Linguistics: Linguistics is considered as scientific study of language.
Linguistic Area: A geographical region determined by shared linguistic characteristics.
0.3. Objectives of the Study
The objectives of this study are as follows:
- Exploring the possibility of interdisciplinary perspective between linguistics and information science since linguistics is used as a representation mechanism for the information content of the document.
- Study of different linguistic theories and their relevance and application to indexing language.
- Study of properties of Kannada relevant to indexing language.
- Survey of technical literature in Kannada, its use for the preparation of a model glossary on education using a bibliometric law.
- Study of different steps in coining the subject headings and problems involved in deriving the descriptors in Kannada.
- Study of feasibility of application of computers for developing IL.
- Application of TG to the NL approach of IL and developing parsers.
- Preparation of a sample PCIL module in Kannada.
0.4. Hypothesis and Methodology
The major hypothesis on which the research is conceived are as follows:
- The need for pre-coordinate indexing language is much felt in Indian languages.
- The concepts of IL can be analyzed in a proper perspective with the knowledge of linguistics.
- Any language, natural or artificial has its structure and vocabulary.
- The pre-coordinate indexing language model derived for Kannada is applicable to all the Indian languages in general and in particular to Dravidian languages.
- The word order of Dravidian languages tallies with the facet structure of IL proposed by SRR in his Colon Classification.
- The use of computer in developing IL,reduces,minimizes the size and quantum of terminology besides simplifying the procedure of indexing,analyzing and problem solving.
- Depending upon the need and the purpose, the parsers have to be developed in the natural language processing environment. The definition Paser may also change depending upon the pupose.
- Generally the IL is free from verbs and and it needs parsers to identify the Noun Phrase(NP) instead of both Nps and Verb Phrase(VP). The following are the methodologies adopted in the present study.Historical metho of IL; survey metho that involves the sociolinguistic study of Kannada background; logical method that involves comparative approach to Kannada and English; statistical method to compile glossary; questionnaire method for eliciting document titles; application of linguistic theories and the use of computerstodevelop parsersin the NLP environment. The freely faceted or analytico synthetic classification system,namely the Colon Classification ,the brain child of S R Ranganathan having the prevalent research on general theory of classification and the techniques from transformational grammar expounded by Noam Chomsky are used as the basis in designing the IL model in Kannada.
0.5. Scope and Limitations
The dimension of IL is so vast that it monitors the whole of universe of subjects. The present study to prepare an IL model in Kannada is limited to a sample in the discipline 'Education', which concentrates on 'Special Isolate' part.of Colon Classification Some of the rules are retained depending upon their suitability to Kannada language. Similarly , for analyzing document titles in Kannada and to develop parsers in NLP environment, Chomskian school of thought is adopted . As for as computer application is concerned, out of the softwares available for processing Kannada, 'Bhasha' and 'Kavitha' software are used for word processing and indexing respectively. Since the present study deals with 'words', the bibliometric model adopted here is the 'Zipf's Law' and the CDS\ISIS package for creating inverted file.
0.6. Chapterization
The chapterization is done in such a way , that it first gives an introduction on IL in general followed by theories of linguistics and finally the way in which the linguistic theory could be practically applied to IL . Chapter one provides the introduction. Chapter two and three provide the methodology . The methodology : adopted from linguistics is transformational grammar, discussed in Chapter two and from information science, Colon Classification discussed in Chapter three. The basic objective of the present study is to prepare an IL module in Kannada..It has to be derived on the basis of structure and properties of Kannada including the technical terminology and rules for generating subject headings. They are discussed in Chapters four five and six. Analysis and interpretation of the data is presented in Chapters seven and eight. The last Chapter presents the inference and findings.
0.6.1. Chapter One: Index and Indexing Language
Chapter one is an introductory chapter to index, indexing language, its role in information retrieval systems and variety of indexing languages.Linguistics is used as representation mechanism in Information Science. By applying theories from linguistics to information science, a new inter disciplinary theme integrating information science and linguistics, 'Infolinguistics' is generated.
0.6.2. Chapter Two: Theories of Linguistics
In linguistics, syntax is discussed in different schools of thought. Since Chomskian school of thought has been adopted for the present study, importance is given here to 'Transformational Grammar'(TG) , its place in linguistics , history and development. Since 'Case Grammar' is most touched topic by information scientists, that is also discussed. Important grammatical categories are introduced here.
0.6.3. Chapter Three: Compatibility of NL and IL
The third chapter looks into the compatibility of NL and IL. Here the structure of IL and Indian languages are compared. If parts of speech such as Noun Phrase, Adjective, etc., are used to analyze NL , fundamental categories mentioned in the 'Colon Classification' such as Personality, Matter, Energy, Space and Time are used to analyze IL.
In the comparative study of NL and IL syntactic structure, it was found that, IL structure was same for each subject in each language where as the structure among the NL was different. Because IL is in the conceptual order and independent of linguistic syntax . Similarity was found among Indian languages taken in the sample and tallied with that of IL. The main reason is that, most of the Indian languages have word order of the type 'Subject Object Verb'(SOV) and English has SVO word order which does not tally with the conceptualized structure of IL.
The Chomskian TG theories are applied to IL in general from first generation 'Standard Model' up to the latest 'Government and Binding' theories that consist of many sub theories. Out of them, it is illustrated with examples that 'Case Theory', 'Theta Theory' , and 'X - Bar' convention are suitable to IL.
0.6.4. Chapter Four: Properties of Kannada
This chapter identifies the properties of Kannada language and literature and they are discussed in detail. This study helps in analyzing the Kannada titles and tagging them with grammatical categories. The properties discussed here are limited to IL analysis.
0.6.5. Chapter Five: Technical Literature in Kannada
The development of technical literature in Kannada in almost all spheres of life stress the need of an IL based on its structure. The fifth chapter discusses technical literature in Kannada, its history, objective, reason, principles used in glossary preparation in Kannada. An experiment is undertaken to prepare a glossary in Kannada (sample) based on bibliometric laws and with the application of grammatical aspects.
0.6.6. Chapter Six: Subject Headings - Pre-coordinate Indexing
The functions involved in generating subject headings are explained taking few existing pre coordinate IL as examples to prepare the Kannada module. The ISO standard is discussed and for the language standardization 'Kannadashaili kaipidi' is taken as the basis . List of Main subjects is rendered in Kannada.Cognitive modules are also discussed and an attempt is made to develop a knowledge representation module based Kannada expert system. It is argued that the purpose and objective of the study should be taken into consideration instead of ritually following the NLP models.
0.6.7. Chapter Seven : Application of TG
If the Chapter two discusses theories of TG,the seventh chapter elucidates the practical aspects of application of TG wherein the following points are discussed:
- The difference between a complete sentence and a document title according to TG.
- The syntactic components involved in a title and their origin from a phrase structure.
- Application of deep structure and the process involved in arriving to surface structure.
- Integration of TG from linguistics,and conceptualization from information science, in order to obtain the structure of IL from document titles in Kannada. To derive rules in (a) the Natural Language Processing (NLP) environment in Kannada and (b) the classificatory structure, an experiment is done by administering the keywords in Kannada among ten experts in a particular field.
0.6.8. Chapter Eight : Illustrating with Examples
Lastly, based on the properties and theories of NL and IL discussed in the previous chapters from one to six, a package is prepared by developing an IL in Kannada. Following are the modules of the package:
- Schedule in Kannada for the discipline 'Education' with the list of subject headings with notation.
- KWIC and KWOC index for titles in Kannada.
*** *** ***
CHAPTER ONE
INDEX AND INDEXING LANGUAGE
| 1.0 | Introduction |
| 1.1 | Infolinguistics |
| 1.2 | Classification |
| 1.3 | Indexing and Information Retrieval |
| 1.3.1 | Indexing Systems |
| 1.3.2 | Varieties of Indexing Systems |
| 1.3.2.1 | Derived or Natural Language Indexes |
| 1.3.2.2 | Mechanized Information System |
| 1.3.2.2.1 | Title Based Indexing |
| 1.3.2.2.2 | Catch Word - Title Indexing |
| 1.3.2.2.3 | Keyword in Context Indexing |
| 1.3.2.2.4 | Keyword out of Context |
| 1.3.2.3 | Citation Index |
| 1.3.2.4 | Automatic Indexing |
| 1.3.2.5 | Permuted Index or Coordinative Systems |
| 1.3.2.5.1 | Pre - coordinate Indexing |
| 1.3.2.5.1.1 | Pre - coordinate Indexing Languages |
| 1.3.2.5.2 | Post - coordinate Indexing |
| 1.3.2.5.2.1 | Computer Based Post - coordinate Systems |
| 1.3.2.5.2.2 | Post - coordinate Indexing Language |
| 1.4 | Conclusion |
1.0. Introduction
Information science is an intra and trans - disciplinary science serving all other sciences with its theory and practice aimed at preparing and providing 'information data' and useful information where ever necessary for the proposed goal, eventually benefiting mankind and its future (Curras, 1992).The present era has been called 'the age of information'. Language is not a barrier to the growth of knowledge.The information flood is extensive and complex but at the same time the human memory has not grown in size. The main focus of information science is to closely match the two states of the mind namely,
- Formal or information generation.
- Informal or information seeking and information utilization.
The 'Text' will be formal comprising of information conveyed by a language in the form of - words→ phrases→ sentences→ paragraphs→ chapters→ and entire text. The volumes of the text will be the unity of the ideas comprising of formal grammar, semantics and other linguistic units. This will be the structure of knowledge.
The user's need in terms of search expression will be informal. Information seeking is its main function. The main constituents are: the thought formulation for a search, and the role of language. This comprises of starting → browsing → connecting→ focusing → and expressing. In this the hierarchy of thought is created.
The following schema presents the two states of mind - Formal and Informal:
The main focus of information science is to closely match these two states of mind i.e.,formal and informal or information generation and information seeking and utilization. Therefore it is necessary to organize information in various levels of technological developments. To cope up with this, information processing system such as search language , reduces information into a set of parameters and projects the contextual relevance.
1.1. Infolinguistics
Theoretical studies of search language require a theoretical framework and a new field of knowledge created through interdisciplinary approach arriving out of 'Information Science' and 'Linguistics', to generate a new field of study called 'Infolinguistics' (Sharada 1995 a , b). Here Linguistics is used as a representation mechanism for the information content of a text of a document. In other words it surrogates information and this forms the main function of Infolinguistics. The representatinal properties of language are syntax and semantics. Syntax deals with the anaylsis of the structure of a sentence and semantics studies the meaning. Keeping this in view Infolinguistics can be defined as syntactic representation and semantic interpretation of natural language for indexing purposes.
1.2. Classification
The new role of search language or classification in information science is to act as filter for information flood. To put it in the words of Ranganathan, SR (1944:
Classification is a lingua franca for knowledge processing and use. A lingua franca with fixed etymology and semantics and a syntax capable of marshaling and presenting it all in most helpful filiatory order is indispensable.
The arrangement of documents is wholly dependent on the indexing scheme that is adopted by the system.
1.3. Indexing and Information Retrieval
"Index is that which serves to direct to a particular point or conclusions"(Clark 1933). In the context of information retrieval systems, index is a mechanism or tool to indicate the searcher, the potentially relevant information to a query. In the library, shelf arrangement and card catalogue are considered as forms of index since they serve to indicate classes of documents.
The first function of an index is to act as a link between a source of information and its user. When size of the collection is quite large, an index is an essential tool for retrieval. A good index minimizes the search effort and ensures optimum results. Index performs a wide and important role in information retrieval system. The indexer is serving as an intermediary between authors and users with the help of Indexing Language(IL) . An IL is a system for naming subjects. It is an artificial language adopted to the requirements of indexing. Like any language, IL also consists of two basic elements:
- Vocabulary - a list of terms used in the system.
- Syntax - the recognized pattern of relationship between the terms used in the system.
If the terms that appear in the documents are used without required modifications,it is a natural language (NL). Since the usage of a NL leads to many problems, such as those arising from the use of different words by different authors to denote the same idea, an alternate to NL is, to use artificial language adopted to the specific needs. Such a language operates with a controlled vocabulary. An IL having controlled vocabulary attempting to indicate the relationship between terms in the index vocabulary is systematically structured.
The artificial language uses concept indexing rather than term indexing. The terms are representatives of a NL used by authors. The concepts imbibe standard description established in the IL. The NL is flexible and advantageous to authors to use different terms to denote same concept. The indexer who is more concerned with the ideas conveyed rather than the language niceties, depends upon artificial language. All the structured IL are based upon careful subject analysis. The vocabulary of an IL is verbal or coded. A classification scheme employs coded vocabulary in the form of its notation.Thus, for example in Colon Classification (CC) Schedule 'Indian History' is rendered as V.44.In Sear's List of Subject Headings which employs verbal vocabulary it is rendered as : India - History. In any case, selection of terms to be used in each discipline is primary and coding is done at a later stage.
1.3.1. Indexing systems
An indexing system is a systemic organization of documents for retrieval . In an information retrieval system (IRS), index will guide or project itself as a guide to the concept in a collection of documents. It informs the existence of documents containing document surrogates, such as author, title, imprint, callnumber etc. An index is a systematic guide to concepts derived from a collection of documents represented by entries arranged in a known and searchable alphabetical, numerical or classified order . In library terminology ,an index is an indicator of content and location or descriptor and locator. In an IRS an index performs two simultaneous functions:
- Retrieving information on documents that are required, and
- (b) holding back information on documents that are not required.
In the context of an IRS, the term index is primarily used as a system capable of retrieving information about required documents based on a particular subject. The principle index is the subject index.
Subject indexing as a process involves four major operations such as:
- Analyzing,
- Arranging,
- Assigning notations, and
- Maintenance of a search file.
The first step is conceptual analysis, deciding what the document is about .The second step is translating the conceptual analysis into index terms, which acts as a label for the subject matter and sequencing them in a meaningful syntactic order called citation order. Third step is assigning notational symbols, which help to retrieve. The fourth step is arranging the entries in a searchable order or maintain a search file.
Linguistically, the text in a document is made up of terms. Request for the document is also made up of terms. Such request is conceptually analyzed and described by means of controlled vocabulary. The request is matched against the search file or index and information about the document is retrieved. The two characteristics of indexing exhaustivity and specificity affect two important measures of an IRS namely recall and precision ,which operate the search stage or output stage of the system (Brown, 1982). The rules of all indexing systems are so designed to increase recall and efficiency and to certain extent, precision also.
Recall: The IRS must be able to retrieve information to the reader's request which vary from a single specific document to a set of articles on a particular subject. The document that is useful to the user's information need, that prompted his/her request may be termed as a 'relevant document'. The ability of the IRS to point at all the relevant documents is known as the 'recall power' of the system which implies quantity. Hence the recall performance of an IRS can be expressed quantitatively by means of a ratio called recall ratio as mentioned below:
R
Recall ratio = -----X 100
C
Where R is the number of relevant documents retrieved against a search and C is the total number of relevant documents to that particular request in the collection.
Precision: In an IRS, index acts as a filter. If Recall is the measure of system's ability to let through wanted items, precision is the measure of the system's ability to hold back unwanted items. The formula for Precision is:
R
Precision = ------X 100
L
Where R is the total number of relevant documents retrieved in that search and L is the total number of documents retrieved in that search. Precision ratio is qualitative one. Usually for a common frame of reference the following terms are used.
- Hit = Every relevant document retrieved. It adds to precision.
- Misses = Every relevant document not retrieved. It adds to the noise.
- Noise = All irrelevant documents retrieved against a search.
- Dodged = Not relevant documents not retrieved.
Information retrieval is the provision of enough (quantity) and relevant (precision) responses to the requests for information. Indexing the concepts based on one of the indexing systems used as a tool, makes information retrieval possible. The IL consists basically an index vocabulary together with means of showing semantic relations to help recall and syntactic device to help precision ).
1.3.2. Varieties of Indexing Systems
Subject indexing systems are the tools with which subject indexes are prepared. It is the index of concepts found in a collection of documents. The following schema presents different kinds of indexing system:
Indexing System
Since the target NL is Kannada for the present study , the examples of document titles are selected from Kannada.
1.3.2.1. Derived or Natural Language Indexes
Indexes for a book can be of three kinds:
- Author index,
- Title index, and
- Subject index.
Conrad Gesture's Bibliotheca Universalize listed the documents under the alphabetical order of the author's fore-name in 1545. Later in 1548, listed the same documents in a subject classification order with an alphabetic subject index to classification codes. This can be considered as the genesis of all the present indexing systems and techniques. In 1856 Andrea Crestadoro, made an attempt to show the importance of titles of documents in cataloging work. Later in 1959 H.P.Luhn of IBM ,utilizing the power of computers developed a new indexing technique called Key Word Index in Context (KWIC). From the 1970s with the rise of Selective Dissemination of Information (SDI) services, titles of scientific documents began to play a significant role in science communication. The title based indexes depend upon manipulation of all the key words in the title to give multiple entries,one entry for each significant word. Attempt is not made to use our own knowledge of the subject or other guides but only the information manifest in the document to derive indexes is used. Indexing thus derived directly from document is derived indexing.
1.3.2.2. Mechanized Information System
A great deal of research is conducted in the application of computers to the intellectual aspects of information retrieval in: (a) creation of index term profiles for documents, (b) creation of abstracts, and (c) automatic derivation of classificatory structures that display relation between document classes, etc. Computers help to process large quantity of data at very high speed. Derived indexing involves minimum intellectual effort and is therefore well suited to computer processing which can give a variety of products from the same input. There are several methods to produce title based indexes.
1.3.2.2.1. Title Based Indexing
The title of a document is ambiguous because the author tries to codify the topic or theme of his work in it. In some books a very clear indication of what the book is about will be given in the title. For example, pashu sangoopane mattu kooli saakane.
At the same time some titles will not be of any help to understand the content of the book, because it has been chosen to attract readers attention rather than to state subject coverage. For example, sari hejje. This book deals with error analysis in language teaching.
In some cases, authors choose different words to name their books on the same subject. For example,
hariharadeeva
harihara kaviya eradu ragalegalu
hariharana puraatana ragalegalu
hariharana nuutana ragalegalu
If the significant word in each title is same, such word can be used as a basis for the retrieval system.
1.3.2.2.2. Catch Word - Title Indexing
Catch word indexing is very simple.and suitable whenever large quantity of titles are to be processed. 'British Books in Print' has adopted this method.
1.3.2.2.3. Key Word in Context Indexing (KWIC)
The KWIC is another development of catch word title indexing. The simplest form of machine generated index is KWIC index. The computer ignores all syntactical words such as articles, prepositions etc., and selects remaining words in the title as indexing words, if the system is provided with a stop word list. The result of the machine manipulation is an index of key terms printed in alphabetical order, together with the text immediately surrounding each term or each significant word as entry point appears in a designated middle position while the rest of the title printed on either side. The alphabetical filing is done on the basis of the key word printed in bold letters in the middle.The only disadvantage with KWIC is, it is entirely dependent upon titles of descriptive quality by authors. This is successful in Kannada and is demonstrated in Chapter Eight.
bhaaratada samskrutiya adhyayana
praachiina bhaaratada itihaasa mattu samskruti
pravaasi kanda bhaarata
1.3.2.2.4. Key Word Out of Context (KWOC)
In KWOC every index word is extracted from its context and printed separately in the left hand margin with the immodified title in its normal order printed to the right.
bhaarata -- bhaaratada samskrutiya adhyayana
bhaarata -- prachiina bhaaratada itihaasa mattu samskruti
bhaarata -- pravaasi kanda bhaarata
In this system titles are liable to give rise to a number of entries depending upon the significant terms. Therefore they are normally used as indexes, i.e., guides leading to entries in a separate list, rather than as methods of arrangement of items. This has also been achieved in Kannada and demonstrated in Chapter Eight.
Further enriched KWIC or KWOC gives index entries wherein additional terms are inserted into the title or added at the end. This involves intellectual effort in the selection of additional terms. In recent years there has been considerable pressure on authors to give their papers meaningful titles which can be used in computer generated indexes.
The KWWC - is based on similar principles, except the 'key word with center'. The KEYTALPHA is just modified form with key terms arranged alphabetically . The WADEX is the words and author index. Along with the key words, author will also be indexed.
1.3.2.3 Citation Index
Eugune Garfield was the first to realize the presence of 'a cognitive and moral connection' between sources and their references. He showed the possibility of constructing an index on the basis of a structured list of all references in a given collection of articles, where each cited reference is followed by all the citing documents.
All the documents are likely to contain a list of references or bibliographic citations. This is the way in which author shows the foundation on which the document is prepared. Hence there is a link between the document and items cited in its list of references. This can be inverted and say that there is a link between the original item and the documents citing it or under one cited document, all the citing documents that have cited it are listed. For example: if three papers A,B and C have cited X, then the citation index will list all the citing documents A,B and C under the cited document 'X'. By scanning very large number of documents by means of computer, the citation index can establish a much large number of such links between scientific articles and their citation.
Science citation Index 1961 -
Social Science citation Index 1966 -
Arts and Humanities citation Index 1977 -
These indexes cover over 5000 periodicals. These are scanned and all the bibliographic links found and fed into a computer to generate citation index, corporate index and source index. The citation indexes are yet to be prepared / generated in Indian languages including Kannada.
1.3.2.4. Automatic Indexing
In the present state of art by using computers, there are many ways to derive suitable indexing terms and produce a conventional type of index found at the end of books. Some softwares are designed specifically for the computerized management of structured database. For example: Micro CDS/ISIS devised by the UNESCO Library, archives and documentation services, UNESCO.It is a generalized information storage and retrieval system.This enables setting up of fast access files to facilitate quick search and retrieval of records from a database. One of the files is the field select table (FST) for specifying indexing parameters for the database. The CDS/ISIS provides for the use of five different indexing techniques as mentioned below together with several facilities for formulating search expressions, the interfaces in PASCAL language for strong search in a given field and for thesaurus construction, maintenance and use the system for which it provides a powerful search facility.
The IT Codes are as follows:
| O | Builds an element from each line extracted by the Format and useful for indexing while lining. |
| 1 | Builds an element from each sub field or line extracted by the format. |
| 2 | Builds an element from the string of characters enclosed in angular brackets(< >). |
| 3 | Same as indexing technique 2 except instead of angular brackets use slashes (/../). |
| 4 | Builds an element from each word, prefixed and suffixed with a space. |
To prevent non-significant words getting indexed, a stop word file needs to be prepared for the database.The readers even without knowing full title of the document can get the inputs retrieved with a help of one or two relevant keywords. There are instances where the computer based system contains whole text of documents. In such cases one can retrieve part or all of the text in response to a query. The development in computer technology has made the introduction of such services technically feasible, and are now becoming economically feasible also. This automatic indexing is possible in Kannada using transliteration of the titles into Roman script or with the help of GIST script processor. With the help of GIST the data can be entered in Kannada script in the CDS/ISIS and the terms will be indexed in Kannada alphabetical order.
1.3.2.5. Permuted Index or Coordinative Systems
The Index language helps to index both single concepts and compound subjects made up of number of concepts. As shown in figure 2, coordinative systems can be divided into two namely - Pre and post coordinate indexes. In the pre - coordinate indexing, the subjects including compound subjects are analyzed into its constituent concepts and the concepts are cited in a prescribed sequence to constitute the scheme of classification or subject heading etc. Since all the terms are predetermined in advance in the schedules or schemes of subject headings, the class relationships are expressed once and for all. The indexer or classifier coordinates the appropriate terms at the time of indexing a document. Here, a string made up of terms to denote the concepts found in the document are joined together to represent a document. Since the concepts and their relations are predetermined, the pre - coordinate system is completely dependent upon the concept relations implicit in the assigned index terms to describe the individual document. The classification schemes like Colon Classification, Dewey Decimal Classification, UDC, Alphabetical Subject Catalog, etc., are the examples for pre - coordinate indexing systems. They do the function of arranging documents on shelf, and help in the retrieval of the same from a collection. Since the concept coordination takes place at the input stage (while indexing), this principle is called pre - coordinate indexing.
The ILs like CC based upon the principles of analysis and synthesis are called 'Analytico - synthetic' or faceted classification .In order to classify a compound subject in CC , the indexer must first analyze the subject into its elementary constituents and then locate these elements in the CC Schedule and recombine or synthesize them to form the compound subject expressed in notational terms. The CC does not enumerate compound subjects. Many schemes list or enumerate compound subjects. They attempt to provide ready made notations for compound subjects as expressed in documents. Such schemes are commonly called Enumerative classifications. Example: Dewey Decimal Classification (Brown 1982).
1.3.2.5.1. Pre - coordinate Indexing
The three major areas to be considered for indexing are: (a) Shelf arrangement of books (b) Library catalogues and bibliographies and (c) Book indexes.
- Shelf classification: In present day open access libraries the books are to be arranged in a helpful way to the readers. The most beneficial arrangement is one in which all the related subjects are brought together in a systematic or classified order. Most of the indexing languages like DDC, CC etc., have been devised with this objective.
- Library catalogues and bibliographies : A library catalogue will record the stock of that library. Where as bibliography is not limited to the stock of the library, but has limitations such as national, international, language, subject etc. At the subject level both are alike.The arrangement of catalogues could be:
-
- Alphabetical subject catalogue : Subject entries and cross references are arranged alphabetically in one sequence.
- Classified catalogue : Related subjects are brought together by using notation as its code vocabulary.
- Feature headings : Feature headings are guide cards, each bearing relevant class number and NL term.
- Alphabetico - classed catalogue : Combination of alphabetical approach with helpful groupings of the systematic approaches, where in the headings are indirect. For example: Aluminium will be entered under metals-non-ferrous - aluminium,not under Aluminium itself. With the result all entries on metals will be grouped together under metals.
- Multiple entry system: This system involves multiple entries.
- Unit entry forms : Card catalog usually of the standard size 12.5 X 7.5 cm arranged in the libraries according to the indexing system headings. New cards are added where ever they are needed.
- Book forms : At one time this was popular in public libraries with closed access, where the catalogs were printed in book form.
- COM : Computer Output in the form of Micrographics.
- MARC : Machine Readable Cataloging began in 1966 as a cooperative venture involving 16 libraries other than Library of Congress.
- On Line Catalogs : The catalogs are held by computers with access through on - line terminals.
- Bibliographies : These are normally printed and intended for vide distribution. It may be current or retrospective.
On the whole these pre - coordinate systems are basically one-place systems following the citation or significance order. At the search stage pre-coordinate systems present certain advantages. Number of searches can be conducted simultaneously. Pre - coordinate systems, which have been severely criticized in recent years by advocates of post-coordinate methods, are yet to be restored to their previous importance by the computer revolution.
1.3.2.5.1.1. Pre - Coordinate Indexing Languages
The key part of a classification scheme is the Schedule - the index vocabulary. The following indexing languages are widely used:
- The Decimal Classification of Melvil Dewey This is considered as the first ILin library classification. This is used mainly in the public libraries.
- The Universal Decimal Classification (UDC), originally based on the Fifth edition of the DDC is the Second major scheme. Normally, widely used in special libraries.
- The Bibliographic Classification of H.E.Bliss (BC)
- The Colon Classification of S.R.Ranganathan (CC)
- The Library of Congress (LC)
- Subject headings used in the dictionary catalogues of the Library of Congress (LCSH).Basically LC is intended for shelf arrangement and is complemented by an alphabetical subject catalogue arranged according to LCSH.
- Sear's List of subject headings
The above mentioned systems are available only in English and some other foreign languages but not in any of the Indian languages. There are some more schemes like the subject classification of J.D.Brown (SC) etc. They are not in vogue in many libraries. The classification schemes mentioned above relied on main classes or the traditional disciplines. But in the present information era research in all disciplines have given rise to interdisciplinary topics. To take into account these new topics, research is conducted in the field of IL.For example : Classification Research group (CRG), Broad system of Ordering of UNISIST (BSO), PRECIS, POPSI etc.
PRECIS: The PRECIS is abbreviation of Preserved Context Indexing System. This was designed to generate subject heading with the help of the computer. This is one of the best currently available system based on more than 20 years of experience in the detailed index of books for BNB, and also theoretical work carried out by CRG. This is an alphabetical subject building system based on the semantic and syntactic characteristics of the language. The syntactic relationship are shown by a set of role operators. In the NL, the passive voice form is preferred over the active voice (Austin 1984).
POPSI: The Postulate-based Permuted Subject Indexing (POPSI) was developed through logical interpretation of the deep structure of subject indexing language (SIL). The POPSI draws attention to the helpfulness of adopting a suitable device for ensuring an optimally effective organizing classification through the alphabetization of verbal subject - propositions. The POPSI prescribes the use of apparatus words - such as prepositions, conjunctions, participles etc., as and when necessary to communicate the exact meaning of subject - propositions. These words are put in parenthesis and they are ignored in alphabetization. Since the POPSI - Index are all verbal entries,filing them in one alphabetical sequence in a unipartite index is made easy. The POPSI procedure involves: (a) Analysis (b) Formalization (c) Standardization (d) Modulation (e) Organizing classification entry (f) Terms of approach (g) Associative classification entries and (h) Alphabetization. One of the POPSI's special features is its technique of generating and organizing classification by juxtaposition of subject propositions in the verbal plane (Bhattachrya 1990).
1.3.2.5.2 Post Co-ordinate Indexing
The Systems allowing class relations to be exploited by manipulation of classes at the time of searching are contrived as post coordinate system. In this, the documents are indexed by terms denoting individual concepts.The headings are single concepts,each containing the code or accession number of the document. This allows free manipulation of terms at the time of search to retrieve information of documents with any logical combinations. This co-ordinates single concepts to build up composite subject at the output stage instead of at the input stage. The use of post coordinate system implies the use of some new kind of physical medium rather than the conventional card catalog. Few of the manual post co-ordinate indexes are : (a) Unit term (b) Optical co-incidence card and (c) Peek - a - boo.
In the words of Collison, Robert (1959),
One of the most exciting experiments in indexing in this generation is the process invented by Mortimer Taube and his associates in documentation. It is based on the unit term system of coordinate indexing. The theory is that each title,each article etc.,can be reduced for indexing purposes to a number of basic ideas capable of being represented mostly by single terms.
Early proponents of post - coordinate indexing claimed that, to select the correct key words it was sufficient to read through the document to be indexed and underline the significant words (Fosket 1981). This process will not take into account the synonyms and cannot demonstrate any kind of relationship. To achieve good results under normal conditions ,it is better to use control vocabulary with post - coordinate indexing ,as done in pre - coordinate indexing. While selecting the terms, preferred term has to be selected and refer to it from synonyms, distinguish homographs and be aware of semantic relations. The need to refer from the subject file to accession file is a disadvantage of post - coordinate systems. This makes searching more tedious then card catalogue. To overcome this, two methods have been suggested. A Master Matrix with a micro - image of an abstract of each document at the appropriate position on which peek - a - boo cards are super imposed and those images where the presence of holes in all the cards permit it are projected one at a time on to a screen. The second method is a development of dual dictionary, using a computer. It is simple to print out the contents of post-coordinate index in the form of series of headings under which document numbers are listed. The contents of a set of unit term cards are transferred to a printed sheet. If two such printouts are made and bound up side by side, comparing the entries are made easy under two headings. Still easier would be, if brief details of each document are printed out in one of the list by the side of each accession number. It is helpful in locating relevant document (Fosket, 1981). None of these systems are tried out in Indian languages.
1.3.2.5.2.1 Computer Based Post - Coordinate Systems
Majority of computer based systems are indexed by Post - coordinate methods or use text searching except few pre-coordinate systems like PRECIS, BTI etc. Few examples of computer based systems are: MEDLARS, ERIC, CAS, and ISI.
MEDLARS: The Medical Literature Analysis and Retrieval System is typical of a very large number of data bases linked to the production of a printed index. This is one of the first model of computer - based services depending upon intellectual indexing. The Demand searches, SDI Service, on-line access system etc.,unique features of MEDLARS. Other data bases have benefited from this pioneering work.
ERIC: The Educational Resources Information Center serves as a clearing - house for Educational Information. This is established keeping in view the publication of increasing number of reports with out adequate bibliographic control. The Journals, Resources in Education and Current Index to Journals in Education cover report literature from 1966 and 1969 respectively. The reports are given ERIC document number. The ERIC Thesaurus is also available in the machine readable form to perform the searches.The full database is available through various utilities, like DIALOG, AUSINET etc.
CAS: The Chemical Abstracts Service is a very important abstracting services in the field of Science and Technology. The whole operation is computerized. Once the abstracts have been produced and key words allocated, DIALOG has a file CA search.
ISI: The Institute for Scientific Information ISI uses only manifest information like authors, titles, citations and bibliographical references.Since 1964, Science Citation Index is produced. In 1973, Social Science Citation Index was set up to cover the areas of Social sciences. The Arts and Humanities Citation Index is also produced by ISI to cover the humanities disciplines. The Citation indexes are computer based. They lend themselves to variety of users. A substantial part of the database is available through DIALOG.The MEDLARS and ERIC use controlled descriptor vocabulary for indexing, while CA uses keywords and titles. In all, text searching techniques may be used to search the NL sections of each entry.
1.3.2.5.2.2 Post - coordinate Indexing Language
A post-coordinate indexing language consists of a set of terms selected for use as indexing terms or subject descriptors. Usually the terms are arranged alphabetically. Though these indexing terms are very similar to the lists of subject headings used in pre - coordinate indexing, post - coordinate indexing language employs only a limited degree of pre - coordination of terms. The indexing terms are not in the form of compound subject headings but are indexed according to their individual constituent concepts. The post - coordinate indexing language is also referred to as THESAURUS. Some thesaurus are alphabetical listings and some incorporate classified arrangement of concepts.The function of a thesaurus is to control the use of synonyms and word forms. Under each of its preferred indexing terms a thesaurus links related terms representing concepts related in a genus/species relationship indicated by:
BT : Broader Term - more general
NT : Narrower Term - more specific
RT : Related Term - is a non genus/species relationship but relationship between a thing and an action performed on that thing. Science and Technology were first to prepare the IL for post coordinate indexing. The most widely used post-coordinate scheme is EJC thesaurus used by limited number of libraries. Most libraries using post-coordinate indexing method tend to generate their own lists using one of the major lists/thesaurus as a model. Two such examples are 'EJC Thesaurus' and 'Thesaurofacet': a thesaurus and faceted classification for Engineering and related subjects. Since these two are complementary than parallel, in the later, both classification and thesaurus have to be used together for best results.
A Few more post-coordinate indexing languages are:
MeSH: Medical Subject Headings - a thesaurus.
BSI Root thesaurus: It is based on original principles of Roget's thesaurus.
Roget's thesaurus: It is a systematic list accompanied by an alphabetical display.
Some of the thesauri in the Social Sciences are:
ERIC: Information retrieval thesaurus of Education terms
Semantic code dictionary of Education
London Education classification
EUDISED multilingual thesaurus
The research is in progress to develop post-coordinate indexing languages in Indian languages.
1.4 Conclusion
Since enumerative schemes do not have a clear facet structure in which the most important focus cannot be identified, Ranganathan, S R's Analytico synthetic or free faceted structure is adopted for the present study. His postulates and principles for concept categorization and knowledge organization give rise to a subject structure and organization of subject in a sequence that is acceptable by specialists in different subject areas (Neelameghan 1992). His theory of classification divided the task of classification into three planes of work.
- Idea plane which deals with classification of ideas into a hierarchical order.
- Verbal plane deals with standardization of terminology, and
- Notational plane deals with assigning a class number to the idea.
Hence, his theory of classification forms an excellent basis for indexing irrespective of any NL. The index language though an artificial language , is dependent on the NL expression. In order to understand and analyze NL expression in a given context, it is expected to have knowledge of Linguistics in particular, syntax, semantics, lexicography etc., so that concepts can be analyzed in a proper perspective. Linguistics is used as a representation mechanism for the information content of a document . This is the main reason for introducing infolinguistics (Figure 1) in between dual states of mind. A trial is made to get the solution from NL analysis by applying transformational grammar to IL in general and Kannada in particular. The next chapter discusses various aspects of transformational generative grammar and semantics.
*** *** ***
CHAPTER TWO
THEORIES OF LINGUISTICS
| 2.0 | Introduction |
| 2.1 | Historical Development of American Linguistics |
| 2.1.1 | Post-Bloomfieldian Theories |
| 2.2 | Syntax |
| 2.2.1 | Transformation |
| 2.2.2 | First Generation Syntactic Structure |
| 2.2.3 | Aspects Model - Standard Theory |
| 2.2.4 | Extended Standard Theory (EST) |
| 2.2.5 | Revised Extended Standard Theory (REST) |
| 2.2.6 | Government and Binding |
| 2.3 | Case Grammar |
| 2.3.1 | Definition of Case Categories |
| 2.4 | Semantics |
| 2.4.1 | Semantic Relation |
| 2.5 | Conclusion |
2.0. Introduction
In the previous chapter it was stated that linguistics is used as a representation mechanism for the information content of the text of a document . The representational properties of an NL are syntax and semantics The present chapter deals with syntax and semantics. In linguistics, syntax has been discussed in different schools of thought. Since , for the present study Chomskian school of thought is adopted, prominence is given to that and explained in detail.
A Natural language (NL) is the primary medium for human communication. The term language refers to the totality of utterances that can be made in a speech community. The scientific study of language is linguistics. Hocket (1942) explicitly defined the nature of linguistics to be a classificatory science, with a linguist's task of classifying data.
2.1. Historical Development of American Linguistics
Linguistics has built up a tremendous body of new knowledge concerning the nature and functioning of human language since the last quarter of the nineteenth century. The period from 1875 to 1925 saw an increasing variety of language and dialect surveys with constant improvements in the techniques of making the surveys and interpreting the data (Whitney 1975). In 1926, Leonard Bloomfield published his work 'Postulates for the Study of Language'. The most important publication concerning the scientific study of language was his work 'Language' (1933). According to him the central concept in linguistic analysis is structure. It is the ordered or patterned set of oppositions which are presumed to be discoverable in a language (Floyd 1961). Linguistics in the 1950s was dominated by the 'American Structuralism' or 'Descriptive Linguistics'. As Palmer states,
For many years from 1930 until the late 1950s, the most influential school of linguistics was one which is usually described as 'Structural' and associated chiefly with the name of the American linguist Leonard Bloomfield (Palmer 1971).
Bloomfield worked out his philosophy of grammar within the behaviorist boundaries. The research was restricted to observable. The most observable feature of language systems is the sound system or phonology. The Morpheme is the minimum meaningful unit of expression.
The post-Bloomfieldian linguists envisaged language in a very precise and limited way and postulated that it has not only a phonemic-morphemic structure but also the structure can be discovered by a set of procedures. This postulates that - phonemes should be found first and then the morphemes. This meant that phonemes had to be found without reference to the morphemes and both had to be found without reference to meaning (Semantics). Though theoretically it was possible, no linguist tried to do this in actual practice because it was practically impossible. Bloomfield stated that morphemes consisted of phonemes. The morpheme '- ing' for instance consists of the phonemes /i/ and /n/. He further stated that morphemes belong to various 'Form Classes'. Combination of such classes with different constructions and meanings are possible. Before stringing of morphemes together, the classes have to be identified first and statements about which classes may combine with which one will be made next. Here classes means 'a set of phonological segments that have more features in common'.The 'Discovery Procedure'(DP) was the result of linguistic research carried on by Bloomfield and his followers. It is a mechanical device that accepts as input a set of data and yields as output a grammar. For example: If enough data from some language is given to the computer with a program, it will construct a fully explicit and accurate grammar for that language. One of the first problems encountered was that of classification of the material being dealt with. This was approached by means of an attempt to formalize the traditional notions of 'Parts of speech'. The division of words and phrases into Noun, Noun Phrase, Verb, Verb phrase, Adjective, Adverb, Clitic, Particle etc., was called Immediate Constituent Analysis (ICA)(Grinder & Elgin 1973).
Sentences are not merely strings of words in an acceptable order and `making sense'; they are structures of successive components, consisting of groups of words and single words. These single and groups of words are called constituents. The ICA is basic to syntax. The ways in which the longer sentences are built up and analyzed into short basic sentence patterns are Expansions (Robins 1971). One of the best method to display I C Analysis is to use the principle of the Family Tree.
Example: An old man with a stick followed the woman.
The expansions in this sense, is not literally expansion. But it is a technical term for the substitution of one sequence of morphemes for another. If we consider the above example, 'The old man with a stick' can be replaced by the name of the person who is having the stick and in the similar way the name/relationship of the woman may be replaced in the second half of the sentence.
Rajan followed his wife Or Rajan followed Sita.
The principle of expansion is derivative from the principal of substitution. By using this procedure,the linguists were able to arrive at an abstract structural formula that represented relationships present in the sequence under consideration. This operation of substituting one sequence of morphemes for another one to arrive at a conception of expansion was first derived by Zelig Harris and further developed by Rulon Wells who suggested the class abbreviation to traditional terms such as N(oun), V(erb), A(djective), T(article), the analysis of sequences of the above example resulted in structural formula such as:
An old man followed the women with green sari
| And | old | man | followed | the | woman | with green | sari |
| T | A | N | V | T | N | A | N |
The major conceptual break through seems to be the proximate cause of the development of transformational grammar by Harris. He first determined the classes on the basis of their co-occurrences of patterns of distribution and finally presented the notion Transformation itself. This was revised and refined by his student and collaborator Noam Chomsky. Since 1957 extensive developments have taken place in the theory and finality is yet to be reached.
2.1.1. Post-Bloomfieldian Theories
One of the most prominent post-Bloomfieldian theories is the Transformational Generative Linguistics (T G Grammar in short).The TG incorporates a full theory of language description, which takes series of rules. These rules based on the theory underlying them are said to generate the grammatical sentences of a language. The term 'generation' does not mean the literal production of the sentences, but the prediction of the forms that sentences when produced will take in the language. The study of the principles and processes by which sentences are constructed in a particular language is called Syntax.
2.2. Syntax
The 'Syntactic Structures' by Noam Chomsky (1957) introduced to the world the most influential of all modern linguistic theories 'Transformational Generative Grammar'. According to him Language comprises a number of components. The syntax of a language contains a phrase structure component and a transformational component. In phrase structure the assumed largest unit of grammar, the sentence [ S ] is progressively expanded by the application of rules into 'strings' of smaller units because in TG sentence is the basic unit of the syntactic system.. Instead of beginning with actual sentences, directions for generating structural descriptions of sentences are set forth in PS rules. Each rule provides a symbol representing a constituent of a sentence to the left of an arrow and a symbol or series of symbols to the right. The following are the symbols used in P S rules:
| S | Sentence |
| NP | Noun phrase |
| VP | Verb phrase |
| N | Noun |
| V | Verb |
| T,art or D | Determiner |
| Pron | Pronoun |
| Aux | Auxiliary |
| M | Model Auxiliary |
| Be | The verb Be |
| Pred | Predicate(noun,adjective,adverb) |
| Vt | Transitive Verb |
| Vi | Intransitive verb |
| Vl | Linking Verb |
| Comp | Complement(noun or adjective) |
| Adj | Adjective |
| Adv | Adverb |
| PP | Prepositional phrase |
Unlike the tree explained in IC analysis,these diagrams are called labeled trees,because each successive representation of S consists of structural elements with a grammatical designation(NP etc.,) called nodes. The tree diagrams are also called 'Phrase Markers' which show the hierarchical structure of the sentence.
2.2.1. Transformation
The term transformation means 'to convert'. In the context of grammar it is to convert a sentence with a given constituent structure. For example, while converting an active sentence into a passive sentence, the position of nouns or noun phrases have to be changed inserting 'by' before the second NP in the passive and at the same time changing the verb from active to passive form. This is a best example for transformation. In 'Syntactic Structures' Chomsky handles the active passive relationship by saying that
if S1 is a grammatical sentence of the form
NP1 → Aux - V - NP2, Then the corresponding string of the form
NP2 → Aux+be+en - V - by+NP1 is also a grammatical sentence.
Here Aux refers to tense and all auxiliary verbs ,while be+en (en stands for the past participle) provides the passive element. The dashes and plus signs can be ignored. Upon the output of the PS rules, Transformation(T) rules are applied to give the final output of the syntactic component of the description. The T rules involve not the division of the sentence into smaller parts, but the alteration or rearrangement of a structure in various ways.
The stages of development of TG are as follows:
- The first generation TG - Syntactic Structure
- Aspects - Standard theory
- Extended Standard Theory
- Revised Extended Standard Theory
- Government and Binding.
2.2.2. First Generation Syntactic Structure
The original form in syntactic structure is called the Classical theory by Chomsky. Fundamental to TG is the notion of rule: TG is rule based grammar. The rules are part of the device for generating the sentences of a language. They are instructions for generating all possible sentences in a language. The rules of TG are rewrite rules. Chomsky explained the term syntax as the study of the principles and process by which sentences are constructed in a particular language. He considered phonemics, morphology and phrase structure as linguistic levels which are a set of descriptive devices that are made available for the construction of grammars. He viewed grammar as an instrument that mirrors the behavior of the speaker, who on the basis of a finite and accidental experience with language can produce or understand an indefinite number of sentences and considered language as a complex system. The meaningful sequence of words produced is a sentence. A language produced by a machine was called 'Finite State Language' and the machine itself was called 'Finite State Grammar'. It was graphically represented in the form of a State Diagram.
The grammar can be extended by adding closed loops. Infinite number of sentences can be produced in this way.
The state diagrams are usually represented by arrows tracing a path. The machines that produce language in this manner are known mathematically as 'Finite State Markov Process',and speaker as being a machine. Many languages are not a finite state languages. For example English. Hence the Markov Process cannot be accepted. So, Chomsky thought of a grammar which is more powerful. New form of grammar associated with constituent analysis had rules. The first PS rule breaks up the sentences into its principle constituents.
Example: The students read the book
- S → NP+VP
- NP → T + N
- VP → Verb+NP
- T → The
- N → Students,book
- V → Read
The derivation can be represented in an obvious way by means of the following tree structure:
Sentence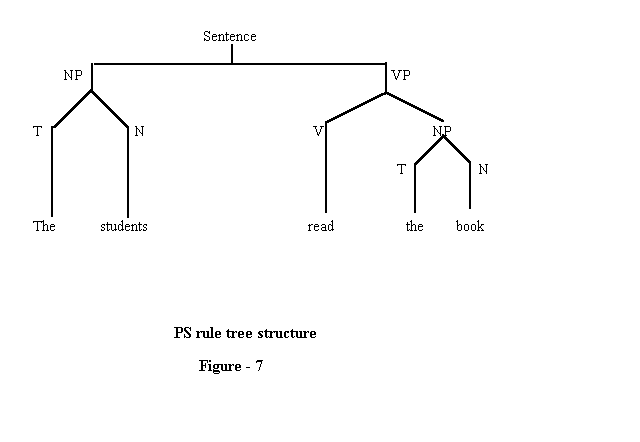
PS rule tree structure - Figure-7
The+students+read+the+book is a terminal string. A set of strings is called terminal language if it is the set of terminal strings for some grammars[ Σ, F ] where Σ the set of initial strings and F set of rules or instruction formulas. Σ can be extended to include declarative,interrogative sentences as additional symbols. Thus,given a terminal language and its grammar one can reconstruct the PS of each sentence of the language as described in the above diagram.
Among the above discussed two models i.e.,Markov Process and Phrase Structure model,the first one was based on a conception of language and the latter was based on Immediate Constituent Analysis. For the purpose of grammar the first one is inadequate and the second one is more powerful than the first. Considerable improvements over grammars of the form [ΣF] gave rise to the process of conjunction which is considered to be the most productive process.
For example, If we have two sentences,
S1 (a) The scene- of the movie - was in India
S2 (b) The scene- of the play - was in India
S3 - The scene of the movie and of the play was in India.
In grammars of the [ΣF] type there is no way to incorporate two sentences. It provides the best criteria for determining how to set up constituents. The next improvement was the study of 'auxiliary verbs'. Even with the verbal root fixed there are many other forms that this element can assume. Example : has+taken, will+take, has+been+taken, is+being+taken etc., the form 'would have been taking' is past tense, perfect(marked by 'have' and the past participle 'been') and progressive (marked by the acorns of 'be' in 'been' and the '-ing' from taking). This is called (be + en) element in the rule which is enumerated as:
Verb → Aux + V
V → hit,take,Walk,etc
Aux → ( (M) ( have + en )(be+ing) (be+en)
M → will,can,may etc
{ S in the context NP singular
C → { 0 in the context NP plural
{ Past
'Be' is the root verb for many verbs like be,an,is,was,are,were,being,been etc. En denotes passive verb(past participle). To transform to passive 'Be+En' formula has to be used.
Example: I saw him
He was seen by me.(where 'was' is the Be verb and "seen" is the "en" form of see). Auxiliary verb is a helping verb in grammatical conjugation.
Example: I am going (am is aux verb).
There are certain restrictions in the usage of this 'be+en'. This can be selected only if the following V is transitive,(Example: 'was' + 'eaten' is permitted but not 'was' + occurred) and it cannot be selected if the V is followed by a NP. It should occur before V+by+NP (where V is transitive). It inverts the order of the surrounding NP.
S1 = NP1 -Aux -V-NP2 Then the corresponding string of the form
NP2-Aux+be+en-V-by+NP1 is also a grammatical sentence.
S1 Raja -S-eats-ice cream.
=Ice cream -S+be+en-eaten-by+Raja. ice cream has been eaten by Raja.
Chomsky, refers to the above said rules as 'grammatical transformation'' or T. T operates on a given string with a given constituent structure and converts it into a new string with a new derived constituent structure. Certain transformations are obligatory where as others are only optional. Passive transformation for example is optional. The rule
S C → O Past is obligatory
The distinction between these two transformations lead to set up a fundamental distinction among the sentences of a language. When only obligatory transformation is applied in the generation of a sentence, a kernel sentence is formed. Active sentences were thus kernel sentences and passives were 'transforms' of them, such sentences are 'derived' sentences. Chomsky stated that transformation is a rule which transforms underlying structures into derived structures or transforms (Chomsky 1956).Since the deep structure was supposed to represent the meaning of the sentence, abstract markers were placed in the later models of the grammar to give positive, negative and interrogative sentences.
(emphatic) S → (imperative)(negative) NP+VP (question)
Question and Negative markers serve as triggers for transformations.
| Kernel sentence | Raja will pass the test. |
| Question Transformation | Will Raja pass the test? |
| Negative Transformation | Raja will not pass the test. |
| Emphatic Transformation | Raja did pass the test. |
| Imperative Transformation | Pass the test! |
| Negative Emphatic Transformation | Raja did not pass the test. |
| Emphatic imperative | Do pass the test! |
| Negative imperative | Don't pass the test! |
| Emphatic interrogative | Did Raja pass? |
| Negative | Didn't Raja pass? |
A universal feature of all languages is their infinite productivity.Even with an unchanging vocabulary the number of grammatical sentences that can be produced has no limit. Though this characteristics of language was noticed by W Von Humboldt over a century ago, it has been particularly emphasized by TG linguists, under the title of the recursiveness or recursion, which means that certain grammatical constructions can be extended indefinitely by repeated applications of the same rule. Thus noun phrases may be coordinated without a limit. Also there is the possibility of repeatedly embedding (subordinating) one sentence structure within the structure of another.
For example, the well known single sentence rhyme 'The house that jack built' exemplifies an extreme application and reapplication of this sort of embedding. The fully worked out tree for this would extend over several pages; with the embedded Ss like S1,S2 etc., and each S should be expanded as NP and a VP.
2.2.3 Aspects Model Standard Theory
It was in the Aspects of the Theory of Syntax nouns are chosen on the basis of context free rules ; verbs are then chosen on the basis of context sensitive rules, which are the terms to express the lexical features. Since nouns are the first words to be chosen,they are identified by lexical features only. Verbs and adjectives require additional features to indicate the environments in which they can appear. Aspects of grammar was organized into three major components:
The syntax, the phonology and the semantics.
The syntactic component had two sub components:
- Base
- PSG Rule
- Lexicon (with rules of lexical insertion)
- Transformational
Syntactic component enumerates the set of tree representations (Deep Structure) that serve as input to other two components. The later two components are called 'Interpretive'. The base specifies fully developed tree structure. The terminal nodes are the set of words and abstract markers that semantic component can interpret the meaning of the tree. These fully specified trees are 'Deep Structures'. The derived tree as a result of the application of T-rules is 'surface structure'.The base contained the lexicon as well as two general types of rules: (a) The Phrase structure grammar rules (PSG Rules) and (b)Lexical Insertion rules. The PSG rules are of two types :(a)Context Free (CF) and (b) Context sensitive ( CS ). The object that resulted from the application of all these rules is a 'Complex Symbol'.This is one of the addition to transformational theory made by the 'Aspects model'.
Example of a tree with complex symbols:
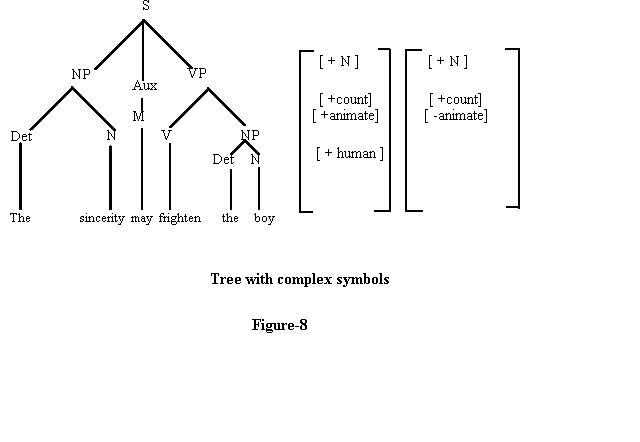
Figure 8
The complex symbol specified what kind of noun could occur under the node of any given tree. In the above example --the N- 'sincerity' is [-Count] [ + Common ] [+Abstract]; May is auxiliary.
The verb 'frightens' is analyzed by rules under the complex symbol 'Q'.
Transformation will preserve the meaning. Deep Structure contains full information to specify the meaning of the tree structure which will be mapped into surface structure by transformation. 'Aspects model' made transformation self evident. (Chomsky 1965). The separation of levels of analysis insisted upon by the structuralist school was respected in the Aspect model ,since the semantic and syntactic components were independent,articulating only at the point of deep structure (Grinder and Elgin 1973). The PSG rules and T-rules handled distinct sets of objects that resulted in formal objects. The surface structure is usually reserved for the result of phonological interpretation of the final derived phrase marker is illustrated below:
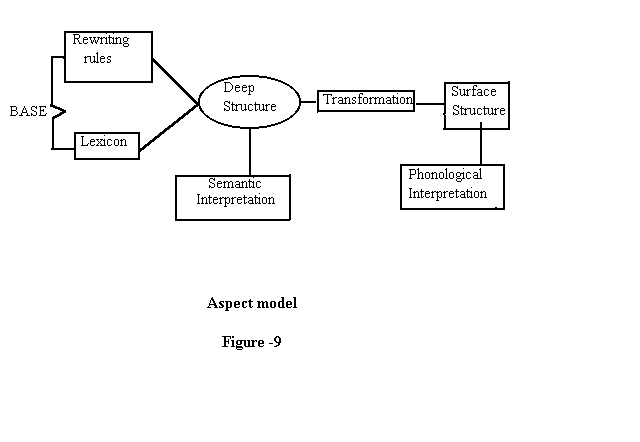
Figure 9
Subsequent research on the role of surface structure in determining the meaning of a sentence has led to the Extended Standard Theory , since some aspects of semantic representation were questioned from the beginning.
2.2.4 Extended Standard Theory (EST)
Ray Jackendoff offered a substantial criticism to the Standard Theory and showed that surface structure played a much more important role in semantic interpretation than the Deep structure. For example , by studying the interaction of negation and quantification within a sentence, Jackendoff showed that their relative position in the surface structure of the sentence was crucial for interpretation (Jackendoff 1965). To incorporate the role of surface structure in determining semantic representation without abandoning the identification of deep structure and semantic representation, generative semantics introduced the notion of 'Global Rules'. These rules relate surface structure to the semantic representation, postulated by generative semantics. It was also proposed that global rules may appear quite generally in the grammar,phonology as well as syntax and semantics. The EST assumes that the rewriting rules of the base, generate deep structure in which lexical items are inserted. Thematic relations between the verb and NPs which are grammatically related are defined at this level. Other semantic properties are determined by rules applying to surface structure. Chomsky introduced the term 'Trace Theory'. Trace in his point of view is that which can be considered as indicating the position of a variable bound by a kind of quantifier which is introduced into the logical form of rules applying to the surface structure. The theory has the following form: The deep structures are generated by the base components with their specific properties. Transformations from surface structures are enriched by traces. These surface structures are associated by further rules for phonetic representation and logical form(meaning),which may be explained as in the following schema:
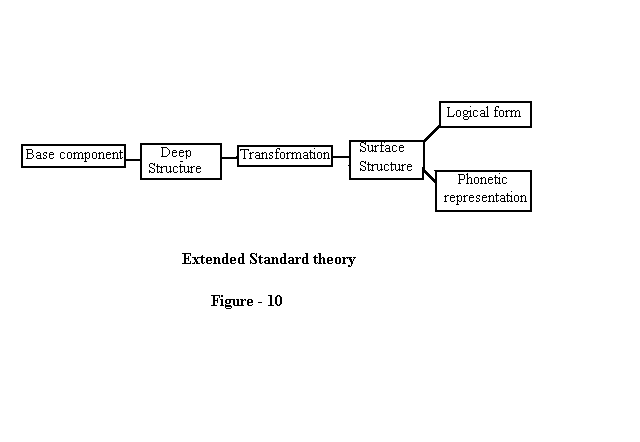
Figure 10
Here the partial representation of meaning is determined by grammatical structure.The derivation of logical form proceeds step by step which is determined by a derivational process analogous to those of syntax and phonology.
The EST maintains that it is not the deep structure that undergoes semantic interpretation, but it is the surface structure that is associated directly with semantic representation. The deep structures do not vary from one language to another. All languages have the same deep structure. Certain properties of underlying deep structure are captured in the enriched sense of surface structure by means of trace theory. Surface structure determines semantic representation. Chomsky further states that surface structure is something quite abstract, involving properties that do not appear in the physical form. It is by virtue of such properties that language is worth studying (Chomsky,1971).
2.2.5 Revised Extended Standard Theory (REST)
There are two principal innovations in the REST:
- Introduction of the trace theory of movement rules into Chomsky's Syntactic theory and
- Semantic skepticism achieves official status, which specifically excluded meaning from the grammatical structure of sentences.
| (A) | B | T | SR1 |
| Sentence Grammar | ------------> | IPM----------> | S---------> |
| LF |
| SR-2 | ||
| Other systems | :LF---------> | "Meaning" |
Chomsky explains that the rules of the base (B) including the rules of the categorical component and the lexicon, form Initial Phrase Markers (IPM). The rules of the transformational component (T) convert these to surface structure (SS),which are converted to logical form (LF) by certain rules of semantic interpretation (SR-1,the rules involving scope,thematic relations etc.,). The LF so generated is subject to further interpretation by other semantic rules (SR-2) interacting with other cognitive structures giving fuller representation of meaning.
The formula A takes into account grammatical properties and relations (like coreference and thematic) to be goals of sentence grammar. Katz (1980) has argued that Chomsky's theory requires sentence grammar to account for the properties and relations and precludes it from doing so,because the boundary imposed in figure A on sentence grammar excludes meaning . He further stated that with the development of the EST and REST , Chomsky returned to his Syntactic Structure with one modification that certain aspects of quantificational structure enter sentence grammar by virtue of new linguistic level called 'Logical Form'. Chomsky suggested that all semantic information is determined by suitably enriched notion of surface structure. In this theory,the syntactic and semantic properties of the former deep structure are dissociated. To avoid confusion resulting from the term deep structure , the same was replaced by Initial Phrase Markers(IPM). The IPMs generated by the base have significant and revealing properties. They enter into SS, determining the structures that undergo semantic interpretation.
2.2.6 Government and Binding
Further addition to TG is the Government and binding theory by Chomsky (1981). It is more explicit and explanatory than the earlier theories. According to this GB theory, the structure of universal grammar (UG) consists of interacting subsystems of grammatical rules and principles.
The sub component of the rule system are as follows(Chomsky 1981):
- Lexicon
- Syntax
- Categorical component
- Transformational component
- PF-component
- LF-component
The syntactic categorical component (2a) involves PS rules that generally follow X - Bar theory in one or another of its variants. The X-Bar theory is the base rules, where lexical entries can be limited to a minimal form with indication of not more than inherent and select ional features and PS rules can be dispensed (Chomsky 1986). The 1 and 2 (a) sub components together constitute the base. Base rules generate deep structure (D-structure). The D-structures are mapped to surface structure (S-structure) by the rule Move-Alpha a which is called the theory of movement. Movement is never determined by specific rule but rather results from the interaction (Chomsky 1986). Move- a constitutes 2(b) generating the S-structure assigned by components 3 and 4.
The subsystems of the principles include the following sub theories or theoretical modules (Chomsky 1985).
- Bounding theory
- Government theory
- -q theory
- Binding theory
- Case theory
- Control theory
Bounding theory possesses locality conditions on certain processes and related items. Government theory is concerned to be relation between the head of a construction and categories dependent on it. The q theory is concerned with the assignment of thematic rules such as agent-of-action, patient-of-action,etc. Binding theory refers to the relations of anaphors, pronouns, names and variables to possible antecedents. Case theory is concerned with assignment of abstract case and its morphological realization. The Control theory determines the potential for reference of the abstract pro nominal element PRO. These modules are interconnected. The third and fifth theories are closely related. The fourth and fifth are developed within the second. Interaction exists between the subsystem rules (A) and principles (B). Bounding theory is connected with the rule Move - a The q theory interacts with both D-structure and LF. The notions such as constituent command (C-command) are found to be central to many of these theories. Through interaction of these subsystems it is possible to account for many properties of particular languages.
The 'Classical' GB model is as follows:
| Logical form | ||
| D. Structure-------> | S. Structure -----------> | |
| Phonology |
Classical GB model
Figure-11
It is also called 'T' model of Chomsky. In the recent past Chomsky is of the opinion that for a substantial core of NLPS rules are completely dispensable, and T-rules also can be eliminated in favor of the general principle Move-Alpha (Chomsky,1991).Within a span of more than four decades the generative syntax has arrived at a conception of Universal Grammar (UG) as virtually a rule free system. In their over view of GB Van Reimsdijk and Williams(1986) state that "From today's perspective most research carried out before the late 1960s appears data-bound, construction-bound and lacking in appreciation for the existence of highly general principles of linguistic organization".
2.3 Case Grammar
The study on TG will be incomplete without a mention of Fillmore's conception 'Case Grammar'. Fillmore is of the impression that grammatical features found in one language show up in some form or other in other languages (Fillmore 1968). The grammatical notion 'case' deserves a place in the Base component of the grammar of every language. The case is one of the underlying syntactic - semantic relationships in a language which make up a universal set of innate concepts that explain judgments about notions such as `who did what to whom' (Palmatier 1972).Case grammar is the modification of the theory of TG. This reintroduces the conceptual framework of core relationships from traditional grammar, but maintains a distinction between deep and surface structure from generative grammar, with the word deep signifying 'semantic deep'.
Sentence → Modality + Proposition
[ S → M + P ]
Modality → Negation, Tense, Mood and Aspect.
Proposition → Tenseless set of relationships involving verbs and noun separated from modality.
Definition of case categories:
Agentive[A]--The case of the typically animate perceived instigator of the action identified by the verb.
Experiencer[E]--The case of the animate being affected by state or action.
Instrumental[I]--the case of the inanimate object controlled by the agent and causally involved in the action or state.
Causative[C]-- The case of the inanimate force causally involved in the action or state.
Objective[O]-- Semantically most neutral case anything representable by the noun whose role in the action or state is identified bysemantic interpretation of the verb itself.
Source[Sr]--The case which reports the location of an object moving away from the locus.
Locative[L]--The case which identifies spatial,temporal or institutional orientation of the state or action identified by the verb.
Factitive[F]-- The case of the object or being resulting from the action or state identified by the verb or understood as a part of the meaning of the verb.
Benefactive[B]-- Is the case of the animate being which is benefited by the result of the action denoted by the verb.
The system of deep case has become one of the modules of generative Government Binding theory under Theta theory (q theory) or the theory of thematic roles (Chomsky 1981). A thematic role may correlate in surface structure with various phenomena like syntactic position, ad position, inflectional suffixes etc (Kiefer,Ference 1992).
2.4 Semantics
One of the three major components considered in the 'Aspects of the Theory of Syntax' in the first complete model by Noam Chomsky was 'Semantics'. Semantics is the study and representation of the meaning of language expressions, and the relationships of meaning among them (Allan, 1992). General notion of semantics is that it studies the meaning that can be expressed. The keynote of a modern linguistic approach to semantics is that "meaning can be best studied as a linguistic phenomenon with 'knowledge of language' and the 'knowledge of real world' "(Leech 1975). A semantic theory is a general theory of language meaning, and should account for the correlation between the sense of language expression and its denotation.Denotation is the relation between language expression and what they denote in words. A semantic theory of a NL is part of a linguistic description of that language (Katz & Fodor 1963). They further state that:
Linguistic description minus (-) Grammar = semantics.
LD-G=S
That is, if the property belonging to grammar is subtracted from the problems in the description of a language, problems that belong to semantics can be determined. Grammar assigns structural description. To determine the domain of a semantic theory the formula LD-G=S may be applied. The speaker's ability to interpret sentences provides empirical data for the construction of a semantic theory. Semantic theory describes and explains the interpretation ability of speakers by accounting their performance in determining the number and content of the readings of a sentence, by detecting semantic anomalies by deciding on paraphrase relations between sentences and by marking every semantic relation. A semantic theory interprets the syntactic structure revealed by the grammatical description of a language.
One important component of a semantic theory of a NL is a Dictionary. From the view point of semantic theory dictionary entries consists of Grammatical and semantic section, catering for syntactical and semantic relationships respectively.
2.4.1 Semantic Relation
From the IL point of view the following three semantic relations are worth discussing. They are:
Equivalence
Hierarchical
Affinitive
Equivalence relationship implies that there will be more than one term denoting the same concepts like:
Synonyms and antonyms
Quasi-synonyms
Same continuum
Overlapping
Preferred spelling
Acronyms, abbreviation
Current and established term
Translations
Hierarchical relationship is that of genus to species and whole to part.
Affinitive/Associative includes:
Coordination
Genetic
Concurrent (two activities taking place at the same time in Association. Example: Education-Teaching)
Caused and effect (Example: Teaching-learning)
Instruments (Example: Teaching-Overhead projectors)
Materials (Example: Plastic films)
Semantic relations discussed here are based on Fosket (1982).There is a lively and productive debate in progress concerning exactly how the semantics relates to syntactic rules. It is argued by Di Sciullo and Williams that words are syntactic atoms, determined by principles that are dissociated from syntactic rules. Mark-Baker is of the opinion that the structure of complex predicates. For example: Kill, Murder, Assassinate, Massacre etc., are causative forms based on intransitive-Die and are explicable in terms of the principles that govern syntactic concern (Jones & Kay 1973).
Among the two schools of semantic thought -The Interpretative and Generative semantics, Chomsky and Katz have favored Interpretative semantics which assigned meanings to the output of syntactic rules, which was further developed into X-Bar theory. Generative semantics was a programmatic theory of syntax, using purported meaning components etc. It failed because syntactic phrase markers used do not properly reflect semantic structure.
2.5 Conclusion
We must know how far Transformational Linguistics approach can provide a methodology. For that, the theories discussed here are applied to IL environment in the next Chapter. Also, in the forthcoming chapters, TG is applied to document titles in Kannada and rules are formulated.
*** *** ***
CHAPTER THREE
COMPATIBILITY BETWEEN LINGUISTICS AND INDEXING LANGUAGE
| 3.0 | Introduction |
| 3.1 | Basic Components of IL |
| 3.2 | Fundamental Categories |
| 3.2.1 | Personality |
| 3.2.2 | Matter |
| 3.2.3 | Energy |
| 3.2.4 | Space |
| 3.2.5 | Time |
| 3.3 | Facet Structure |
| 3.4 | Facet Syntax and Linguistic Syntax |
| 3.5 | Sample Infolinguistic Studies |
| 3.6 | Application of TG to IL |
| 3.6.1 | Computer Application of TG |
| 3.6.2 | Manual Application of TG |
| 3.6.2.1 | Application of X-Bar to Document Titles |
| 3.6.2.2 | Application of q Theory to Document Titles |
| 3.6.2.3 | Application of Case Theory to Document Titles |
| 3.7 | Conclusion |
| 3.7.1 | Advantages |
| 3.7.2 | Disadvantages |
3.0 Introduction
Function of a NL is to communicate semantic content of its expression in a simple, direct manner to the receiver. Where as, the function of an IL is to take whatever NL does in addition to the organization of semantic content through a different expression . In this process the expression in an IL becomes different from that of a NL expression. In short, semantic approach needs compatibility between a NL and an IL expression. One more important function of an IL expression is to provide a point of access to the seekers of information. This has to be achieved with minimum distortions.
An IL is made up of expressions connecting several kernel terms. These kernel terms have indicated roles in an index expression in the form of pre-coordinate subject headings at the input stage or post-coordinate search statements at the output or retrieval stage. Therefore, an index expression can be taken as equivalent to a sentence in a NL discourse. An index expression consists of kernel terms in their prescribed sequence of the roles according to indexing principles. It has connectives and conjunctives to make index expression complete.In the last four decades, the development of grammar of IL has a close parallel in the studies of theory of syntax and generative grammar for NL. In the Standard Transformational Grammar (TG) the deep structure of a sentence determines the semantic content while its surface structure determines its phonetic interpretation. In IL the model of deep structure underlying a surface linear ordering is subscribed. In Linguistic notation, as discussed in the Chapter Two, a sentence is formed by Noun Phrase and Verb Phrase. Between NP and VP a relation of predication may be defined. The deep structure of every language is built up on this relation apparently without exception ( McNeill, D 1969 ).
The mapping between the deep structure and its surface structure is the transformation. "Real progress in linguistics consists in the discovery that certain features of given languages can be reduced to Universal properties of language,and explained in terms of these deeper aspects of linguistic form" (Chomsky 1969). It can be inferred that any language whether natural or artificial, will have syntax . The postulates and principles of syntax may change from language to language.
3.1 Basic Components of IL
In the IL, the letter 'S' of NL is substituted by 'Title', 'T'. The person whose versatile and unique contribution is still recognized and adopted at the international level in the field of IL is S R Ranganathan. His notable contribution is in the area of syntactic analysis, structuring and representation of subjects. His General Theory of Classification is based on postulates and the study of the attributes of the Universe of subjects (US) in particular its structure and development. A study of the ideas forming components of the large variety of subjects in the US indicates that they can be categorized into three types:
- Basic Subject Idea (BSI)
- Isolate Idea (II)
- Speciator Idea (SI)
If BSI is a subject without any components, II is a component of a subject but not a subject by itself and SI is a modifier, this when combined with a BSI or II produces a change in their respective connotations. With the combination of these three ideas ,Simple subject (BSI), Compound Basic subject (BSI + SI), Compound Isolate (II + SI), Compound subject (BSI + SI) and complex subject (combination of all) can be formulated. The large variety of isolate ideas occurring in diverse subjects are categorized into seven types by SRR. They are:
| Number | Isolate idea | Manifestation of the fundamental category |
Indicator digit |
| 1 | Time | TIME [T] | . (dot) |
| 2 | Space | SPACE[S] | |
| 3 | Action | ENERGY[E] | : (colon) |
| 4 | Method | ||
| 5 | Property | MATTER[M] | ; (semi colon) |
| 6 | Material | ||
| 7 | Totality of all attributes of an entity taken together | PERSONALITY[P] | , (comma) |
By deeming each of them as a manifestation of one and only one of the five Fundamental Categories ( FC ),the seven variety of II is reduced to Five FC - [P],[M],[E],[S] & [T]. Each facet was given a separate indicator digit. There is similarity between SRR's five FC and Whorf's hypothesis on language, which states that "every language contains terms that have come to attain cosmic scope of an unformulated Philosophy...such as our words like 'reality' 'substance' 'matter' and 'space', 'time'past present and future" (Neelameghan 1972). The Structuring of subjects by SRR is based upon the above said five fundamental categories that center around the concepts of Basic Subject (BS).
3.2 Fundamental Categories
3.2.1 Personality
Personality is the core component which is the manifestation of FC Personality [P]. Taking into consideration the definition of subject as a "system -an assymetric,noncommunicative, centralised system"(Neelameghan,1972).The FC Personality is in conformity with the concept of 'Leading part' in "Centralized system"(Seetharama 1972). For recognition of Personality, SRR suggested the method of 'Residue'. In this method, a kernel idea is correlated with each of the four FC - Time, Space, Energy and Matter in succession and if the kernel idea cannot be deemed to be a manifestation of any one of these four FC ,it was deemed to be a manifestation of the FC Personality. However this was not found to be adequate. Gopinath(1980) has analyzed the problem in identification of FC in interdisciplinary subjects and has framed criteria and methods for the same. He states that "the problem in the recognition of the FC Personality is not definitional,but contextual. The semantic and syntactic aspects in the formation of the compound subjects and the generalization of these structures to a model base ... that is a Basic subject...sets the difficulties in the recognition of Personality"
3.2.2 Matter
As per the above Table 1, the manifestation of Matter is of three varieties namely 'Matter - Material', 'Matter - Property' and 'Matter - Method'. Matter represents a property or materializes of the focal idea of the subject statement. After 1964, the qualifier concept was recognized and lead to the recognition of the material constituent and such qualifiers are known as Speciators.
3.2.3 Energy
Energy connotes some kind of action in relation to the focal idea. Ranganathan(1957) stated "Energy manifests itself either as motion,interaction or mutual action of some kind or as one of the isolates postulated to be Energy, such as those denoted by the term- Physiology,Morphology,Ecology,Disease etc." Any action is termed as 'Energy' facet.
3.2.4 Space
The concept of the FC Space is in accordance with what is commonly understood by that term. The surface of the earth, the space inside and outside it are manifestations of the FC space. The geographical area and physiographic features are manifestation of FC Space.
3.2.5 Time
The Time isolate ideas such as millennium, century, decade, year etc.,are the manifestation of the FC Time. The time isolate of another kind - such as day and night, seasons such as summer and winter, meteorological quality like, wet, dry, stormy etc., are also taken as manifestation of the FC Time.
Keeping in view the explanation of each FC, it is seen that these FCs are identifiable without much difficulty. Postulates and principles provide a kind of typology of generic relations resulting in a Facet Structure which can be used for generating an organized set of subject propositions. The five FCs are interrelated and keeping this in his view, SRR sequenced them as PMEST in order of decreasing concreteness of categories. With the aid of the postulates of FC, rounds, levels, basic facet, canons and principle of helpful sequence of compound subjects going with one and the same basic subject, and in the overall sequence of subjects going with different basic subject has been achieved. Work in relation to the analysis of subjects in terms of categories has been attempted by different scholars .For example: Dobrowolski, Cordonnier and Eric de Grollier, Farradane, Foskett, Vickery, Mills, Kyle, Cerenin, Vleduts, Stockolova, Perry, Kent, Shera and Egan etc. who have used different terminologies which can be grouped or reduced to five FC - PMEST (Seetharama 1972). Among the earlier specialists in constructing IL ,Classification Research Group (CRG) of Britain established in 1948 is worth mentioning. Influence of SRR's idea is discernible in the faceted schemes produced by CRG. Farrandane from CRG doubted and abandoned the idea of Universe of subjects being divided into Basic subjects, Main subjects, Compound subjects etc., and maintained that it was from the universe of concepts that all compound subjects must be ultimately constructed (Palmer & Austin 1971).
Another systematic attempt to design IL for Social Sciences is by Barbara Kyle (1958). She identified only two categories namely, Personality and Activities. Like Farradane she also abandoned the traditional disciplines and arranged all the concepts irrespective of their origin under the two FC, sequence being Activities precedes Personality. The Space and Time are also taken into account.
Linguistically, the subject structure can be designated either by one term or by a more complicated linguistic expression. Usually concepts can be taken up as implicit of a subject. Human minds are able to form concepts which are of an abstract nature (Johansen 1990). SRR (1967) stated that, "the sequence in which the component ideas of compound subjects going with a Basic Subject, usually arrange themselves in the minds of the majority of normal intellectuals." He called this as Absolute Syntax. This postulate helps in deriving principles for sequence of component ideas in a subject.
3.3 Facet Structure
Structure is the way in which the components of an entity are put together. Any thing that has structure has parts, properties or aspects which are related to each other in some manner. Generalized facet structure for subjects are represented by the following schema (Neelameghan 1979).
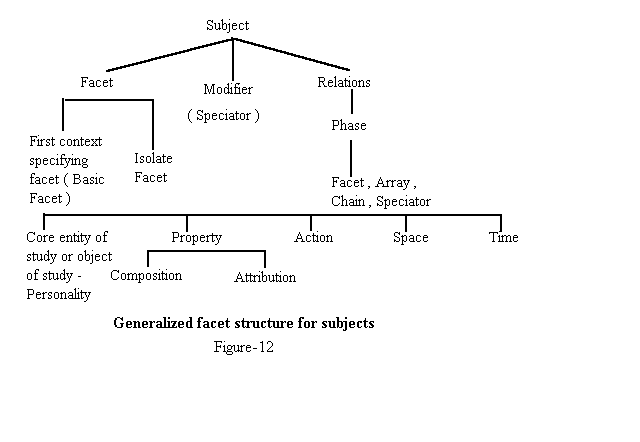
Figure 12
Subject structuring obtained using the generalized facet structure is found to give a co-extensive representation of subjects and arrangement of subjects helpful to a majority of users (Neelameghan 1979). The sequence of facets in compound subjects is called the Facet Syntax(FS). A number of principles have been formulated in FS - such as: (a) Commodity - Raw material, (b) Act and- Action - Actor - Tool , (c) Cow Calf (d) Whole Organ and (e) Wall - Picture principle.One of the principles for helpful sequence is the Wall - Picture principle, because the others are derivable from or are corollaries to it. The other principles for helpful sequence are derivable by the application of the wall -picture principle . This wall-picture principle states that, if two facets A & B of a subject are such that the concept behind B will not be operative unless the concept behind A is conceded, even as a mural picture is not possible unless the wall exists to draw upon , then the facet A should precede facet B (Neelameghan 1971).
3.4 Facet Syntax and Linguistic Syntax
Table - 2 gives the example of difference between Facet syntax and Linguistic Syntax. The facet syntax is based on the wall-picture principle.Table 2
| Language | Subjects in NL | Facet Syntax |
| English | Antibiotic treatment of bacterial disease | Child Medicine, Lung, Bacterial Treatment, Antibiotic |
| Kannada | makkalalli eekaanujiivi swaasakoosa roogada jiivirodaka cikitse |
makkala aarogya,swaasakoosa eekaanujiivi ,rooga,cikitse jiivirodhaka. |
| Tamil | kulandekalin nuraiiral kiriminoykkana antibiotic cikiccai. |
kulandekalin aarokyam,nurai iral,kiriminoykkana,cikitsai, antibiotic. |
| Telugu | pillala uupiri tittilaku cendina krimimuulaka vyadula kriminasaka cikitsa |
pillala aarogyam,pirititti, krimimuulaka, roogamu, cikitsa,kriminasaka. |
| English | The sociology of alchoholism among middle - class people in developing countries 1950-70. |
Sociology,Middle-class, Alchoholism,Developing Countries,1950-70. |
| Kannada | abhivruddhisiila raastragalalli madyamavargadavara meele madyapaanada prabhava 1950-70. |
samajasastra, madyama varga, madyapaana, abhivriddhisiila, raastra 1950-70 |
| Tamil | munnerum naatkalil naduttara makkalidaye kutippalakkam parriya samuuka vijnanam.1950-70 |
samuuka vijnanam,naduttara makkalidaye,kudippalakkam munnerum, naatkal, 1950-70. |
| Telugu | abhivriddi chendutunna desalalo madyataragati, prajalapai saaraa prabhavampai sangika pariseelana.1950-70. |
|
| sangika sastram, madyataragathi, prajalu,saaraa,prabhavam abhivriddi cendutunna desam 1950-70 |
The facet syntax derived on the basis of the postulates and principles particularly the wall - picture principle of the General theory of Library Classification is same for each subject in each language, which is in the conceptual order and independent of linguistic syntax, although the linguistic syntax differs from language to language. This is because, the word order is different in each language. For example, word order of English is in the order Subject Verb Object (S V O) . Most of the Indian languages have S O V word order. Taking the above Table-2 into consideration, at the outset , if we take the three concepts and tally with word order, S will be Child , O will be bacterial diseases of lungs, V will be Treatment. Hence the facet syntax will tally with the S O V word order of Indian languages.
Another faceted scheme much influenced by SRR's ideas is the Broad System of Ordering. The basic facet pattern embodied in particular subject field is as follows:
- Tools or equipment for carrying out operation.
- Operations (Purposive activities by people).
- Process,interaction.
- Parts,subsystems,objects of action or study.
- Objects of action or study,products or total system. Example : 'Child welfare in disaster relief.' 575,32,0,73,50
In the above BSO Code number, the first element in combination order, namely the concept Child belongs to facet 5, the second element, the process which requires a welfare operation to be undertaken, namely the concept Disaster belongs to facet 3. Facet 4 is not applicable to this. Though facet 2 is applicable, it has no role in this combination. Welfare defines the whole combination area. Facet 1 would be applicable if a particular Welfare Agency was to be specified. The citation order within the subject field is regularly the reverse of the scheduled sequence of the element concerned, which is quite similar to the PMEST order of SRR which is in the order of decreasing concretness of categories. Neelameghan (1971) suggested a model of deep structure underlying a surface linear ordering using the wall - picture principle. Harris and others (1979) agreed with this model but instead of wall - picture principle they followed 'General to Particular' and 'Abstract to Concrete' principle. For example: The whole sequence begins with the very broad category that constitutes the basic subject and its entire literature - and ends in the 'External Dimension' with the physical particulars of the document The 'Internal Dimension' leads to particular linguistic acts, errors and objects.
In Faceted Information Retrieval for Linguistics (FIRL), Harris (1979) considers among the five FC, the core component Personality facet represented at one level by the sub - disciplines and theoretical schools of linguistics and at another level by characterization of the language speaker. Energy is clearly the speaker's performance. Space and Time turn up in that order in dialect and historical period.Hemalatha Iyer(1990), while discussing the transformational rules to NL representation, states that the facet structure of a subject proposition can be correlated to similar structure in linguistics. She finds a parallel in the inter - constituent structure of a formal language in Halliday's (1976) System and Structure and makes a comparison between linguistic structure and facet structure and formulates rules for transformation from facet structure to NL representation. She infers that pre - coordinate index string would facilitate collocation and browsing while the NL representation would help the user to interpret the subject of the document accurately.
The terms in IL should be grouped in a location in an exhaustive manner so that searcher can get the information in a short time. Since IL suffers to certain extent in syntax and semantics in extending semantics for the searcher, the question is, 'Is there any way to help the users without changing the meaning?'. Though the grammar like PMEST gives an efficient typology to indexing purposes, it does not work in favour of NL. This has support with Iyer's statement that "Facet structure representation is not as effective as NL in communicating the subject of the document to the user" (Iyer 1990). We have to test whether theories from modern linguistics like Transformational Grammar are able to give much better compatibility to IL, in particular, Indian languages.
3.5 Sample Infolinguistic Studies
Information scientists have worked on problems like - Linguistic research in classification and information processing in the following areas (Neelameghan 1982):
- Linguistic problems in natural language interactive inquiry systems.
- Multi - lingual thesauri.
- Input output problems in multi - lingual information networks.
- Mechanical linguistic aids in thesauri development.
- Languages for control and access as related to both data entry and inquiry.
- Semantic and conceptual foundations of classification.
3.6 Application of TG to IL
3.6.1 Computer Application of TG
Based on Chomskian phrase structure grammars, parsers have been developed which represent a sentence in a tree structure. As programming language, Definite Clause Grammars (DCG) is the basis. PROLOG (Programming in Logic) is one of the most popular in Artificial Intelligence programming. Finite State Transition Network (FSTN),Recursive Transition Network (RTN),Augmented Transition Network (ATN), etc., are some of the computational models. FSTN parsers are useful in dealing with very limited subset of a natural language with limited vocabulary. Finite State Grammars are not recursive. Hence, RTNs were developed which has subnetworks and build large networks in a modular way. Any RTN which allows additional tests and store information on the labels are called ATN. It can store information in registers and provides registers for each subjects like Noun phrase, verb phrase, etc. At the end of parsing, the contents of registers are grouped to form a valid sentence structure. Until then, ATN keeps on trying alternative sentence structures (Prasad 1992). In the present context, in addition to the syntactic models, semantic models are also being developed.The input sentences are transformed through the use of domain dependent semantic rewrite rules which create the target knowledge structure. Contextual Dependency Grammar, Modular Logic Grammar are few examples for this. Salton (1984) hopes that, new developments may render the linguistic techniques more attractive in future.If a sentence like the one given below is fed to the computer:
'Students read lessons'. This sentence is analyzed as:
[S[np, [n, students] ], [vp, [tv, read] [np, [n, lessons]]]]
3.6.2 Manual Application of TG
To exploit internal similarities of the major categories, Chomsky devised X - Bar convention, to show the occurrence restrictions holding within sentences. He has shown how the internal structure of the derived nominals reflect the sentence.Word categories like Noun, Verb, Auxiliary etc., are lexical categories. Whereas NP, VP, Adj ph, Pre ph, Adv ph and S as the non - final; nodes/ phrase markers. There are intermediaries which are neither lexical nor phrase markers. For these type of representation X - Bar convention is used.
XP = Phrasal category, X = Intermediary, X = lexical. However, now, linguists mix the bar convention and the phrasal category convention. The central idea in the X - bar theory is that the PS - rules determining the structure of phrases containing their head can be stated symmetrically in terms of structures as mentioned below schema, where N is the head, every thing to the left of N is specifier, and every thing to the right of N is complement.
The X - Bar notation can be adopted to show the hierarchical relation among IL categories where N is the maximal projection of a NP and N is the minimal projection of a NP.
3.6.2.1 Application of X - bar convention to Document Titles
In the context of IL, N may be equated to the Title (T), of the document and modifiers may be equated to PMEST according to hierarchical relation. For example : 'The sociology of alchoholism among middle class people in developing countries, 1950 - 70'.
T=1950 - 70
S = Developing countries
X = Title
P2 = Alchoholism
Modifiers= PMEST facets
P1 = Middle class people
BS = Sociology
Among the other sub theories of Government and Binding (GB) Binding theory, Government theory and Control theory cannot be applied to IL because, the parameters of the former are related to NL sentences and the later is dependent upon the understood elements in NL sentences. Likewise Move a also . Other than the X- Bar theory as explained above, the theories suitable to IL to a certain extent are q Theory and Case Theory.
3.6.2.2 Application of q Theory to Document Titles
q Theory :- Example- 'Growth of Cottage Industries in Karnataka'
3.6.2.3 Application of Case Theory to Document Titles
Every NP must get a case. For example :There are three cases - Nominative, Oblique and Possessive. If AGR assigns nominative case to the subject, the verb assigns oblique case to its direct object and the pre or post position assigns oblique case to its object, and NP in the specified position gets possessive case.
Example : 'Doctor's Diary'
Here, Doctor's is possessive case.
Computer specialists and Linguists are still on the way of developing parsers based on GB theory. Once that is finalized it will be possible to test its application to IL. At present, X - Bar Theory seems to be the module, relevant for the analysis of IL.
In the light of application of semantics to IL, Metaphorical Interpretation seemed better than deep structure. Metaphors for the first sight may seem semantically wrong but interpretation of it provides some specific meaning to it.
For example: 'John is a donkey.'
Semantically it is a bad sentence as 'John' is a human being and cannot be a 'donkey'. Perhaps, it may mean something like , 'Donkey' may stand for symbol of humility and therefore 'John' may have specific attribute to correlate to 'donkey'. For the purpose of IL, if the following Title is taken for analysis : 'Goofican'deals with error analysis in Linguistics. 'Goof' means 'error', 'can' mean list and the answer to 'what kind of error list' can be got from metaphorical interpretation. In the recent days, parsers are developed to analyze the metaphors based on Paninian grammatical theories.However depending upon the needs of IL any methods discussed above may be adopted , because each theory has been developed on specific principles and models.
3.7 Conclusion
The features of NL and IL are summarized in the following table.
Table 3
| Feature of NL | Features of IL | |
| Objective | Semantic | Semantic and Sequence of concepts. |
| Structure | Grammar | Facet Syntax |
| Analysis | Grammatical | Postulational |
| Transformation | Behavioral | Postulational and hierarchical |
| Synthesis | Natural | Postulate- Specified |
| Representation | Natural language | Artificial language |
| Modelling | Behavioral | Hierarchical |
| Lexicon | Dictionary based | Taxonomic/Thesaurus based |
Comparative statements of features of English and Dravidian languages are depicted in the table given below.
Table 4
| Features | English | Dravidian languages |
| Objective | Widest dispersion | Limited dispersion |
| Structure | SVO Word order | SOV Word order |
| Modeling | Behavioral | Hierarchical |
| Sequence | Flexible | Closer to Absolute syntax |
Advantages and Disadvantages of application of TG to IL
3.7.1 Advantages
- Facet structure of a subject proposition can be correlated to similar structure in linguistics.
- Knowledge of TG enables us to identify the concepts according to the category it relates to [Example:Verb = Energy, Noun = Personality etc].
- The sub theories of GB helps in structuring IL from maximal to minimal level.
- The X - Bar theory is helpful in analyzing IL since all phrases have same structure to be analyzed in a similar way.
3.7.2 Disadvantages
- Since IL has the responsibility of representing the whole content of a document with minimum lexicons excluding the structure words, it is likely to formulate phrases shorter than a complete sentence. The parsers developed on Natural Language Processing (NLP), will accept to analyze only complete sentence and not incomplete ones and metaphors. Hence parsers suitable to IL situation has to be developed.
- T G is not a stable theory and it keeps on changing.
The Facet structure of SRR is quite nearer to word order in Indian languages. Since the present study is on Kannada the same has been adopted. Also it is more psychological and intellectual context in indexing, retrieval and search. It helps general browsing and purposive browsing. However ,as NL statement is more effective in communicating the subject of the document to the user, for retrieval purpose, X - Bar Theory may be adopted after developing parsers. The crucial properties and relations will be stated in the simple and elementary terms of X - bar theory (Chomsky 1992).
The properties of Kannada are discussed in the next chapter and tested how far the properties of TG could be adopted for developing the IL.
*** *** ***
CHAPTER FOUR
PROPERTIES OF KANNADA
| 4.0 | Introduction |
| 4.1 | Structural Similarities and Differences Among Dravidian Languages |
| 4.2 | Place of Kannada in Dravidian Family |
| 4.3 | Historical and Sociological Aspects |
| 4.3.1 | Evolution of Modern Kannada |
| 4.4 | Phonology |
| 4.5 | Orthography |
| 4.6 | Morphology |
| 4.6.1 | Pronouns |
| 4.6.2 | Nouns |
| 4.6.2.1 | Simple Kannada Nouns |
| 4.6.2.2 | Derived Kannada Nouns |
| 4.6.2.3 | Compound Nouns |
| 4.6.2.4 | Gender |
| 4.6.2.5 | Number |
| 4.6.2.6 | Case System |
| 4.6.3 | Adjectives |
| 4.6.3.1 | Attributes |
| 4.6.4 | Verbs |
| 4.6.4.1 | Tense |
| 4.6.4.2 | Mood |
| 4.6.4.3 | Aspect |
| 4.6.4.4 | Voice |
| 4.6.5 | Adverb |
| 4.7 | Structure |
4.0 Introduction
Kannada is one of the 1652 mother tongues being spoken in India. It belongs to the Dravidian family of languages. The Dravidian languages stand apart from other family of Indian languages like Indo Aryan, Sino Tibetan and Austro Asiatic by having distinctive structural differences at phonological, morphological, lexical, syntactic and semantic levels.
4.1 Structural Similarities and Differences among Dravidian Languages
In Dravidian languages, phonologically there is a contrast between alveolar, dental and retroflex consonants. Morphologically, there are separate pronouns to indicate the distinction in first person plural in the form of inclusive and exclusive pronouns. There is no morphological distinction between direct and indirect reported speech. At the syntactic level, use of string of participles, that is, a form of non finite verbs for coordinate conjunction. On the lexical plane, the Dravidian languages are characterized by having very less number of adjectives and adverbs as primary lexical categories ; use very large number of onomatopoeic words. Semantically, the Indo Aryan languages have three stems intransitive, transitive and causative ; where as, the Dravidian languages have four fold semantic structure for the verbs like intransitive, causative of intransitive, transitive and causative of the transitive (Annamalai 1990). These characteristics distinguish the Dravidian family of languages from other families . This does not mean that, all these characteristics are present in all the Dravidian languages. Due to long contact among different family of languages they have developedcommon features called aerial features. They include reduplication of words, use of compound verbs, etc. (Emeneau 1956).
Kannada has many of these properties like: string of participles:naanu hoogi, tindi tindu tarakaari kondukondu addaadi barutteene, 'I will go and eat the tiffen, after buying the vegitables, after stroling ,I will return'; less number of adjectives and adverbs; a large number of onomatopoeic words: kota kota, 'that is the way water boils'; fourfold semantic structure of verbs : naanu malagutteene 'I will sleep'(intransitive), naanu niiru kudiyutteene 'I will drink water'(transitive), naanu ninage niiru kudisutteene ' I will cause you to drink water'(causative) naanu avaninda ninage niiru kudisisutteene 'I will cause him to cause you to drink water'.(double causative).
4.2 Place of Kannada in the Dravidian family
So far, twenty seven Dravidian languages are distinctly identified. Depending upon the characteristics that these languages share, they are further classified into four sub groups : South Dravidian, South Central Dravidian,Central Dravidian and North Dravidian languages ( Zvelebil 1995). Kannada is one of the major language of South Dravidian Group. It is also one of the modern Indian languages included in the VIII Schedule of the Constitution of India. It is the mother tongue of nearly 43 million people.
4.3.1 Historical and Sociological Aspects
Kannada has a history of nearly 2000 years. Depending upon the historical changes in its structure five stages have been identified in its development to the present form. They are:(a) Puurvada halagannada up to 600 A.D.(b) Halagannada 600 A.D. to 1000 A.D.(c) Nadugannada 1000 A.D. to 1500 A.D. (d) Hosagannada 1500 A.D. to 1900 A.D. and (e) Aadhunikakannada 1900 A.D. onwards. During the course of its existence of nearly 2000 years, Kannada came into contact with Urdu, Marathi, Englishetc., because they happened to be the languages of the rulers at various stages of history. Also languages like Kodagu, Tulu, Konkani are co-existing with it since hundreds of years. Kannada has undergone natural changes in its structure that any living language will undergo. The influence of other languages is also discernible.
4.3.2 Evolution of Modern Kannada
The urge for freedom of the Nation, increase in contact, communication, interaction, and above all spread of education gave a fillip to the development of prose writing in Kannada. People's hunger for knowledge through their mother tongue also grew. Because of translations from other languages into it and original writings in prose form found new avenues of expression in the form of literary and non literary writings till independence of India. Most of the language development activities during this period were individual oriented and done for the love of the language.
The re - organization of States on linguistic principles provided a basis for giving a single geographic identity for Kannada. And for the language, it gave an organized and institutionalized fillip for expansion and growth. From this point onwards, systematic language activities were taken up by both state and central governments, autonomous institutions etc., to make Kannada as a vehicle of modern thought by using it as a language in education, medium of instruction at as many levels as possible, administration and mass communication. Simultaneously, unplanned language development activities generally undertaken by individual scholars too continued. The social, political, economic and educational changes and development in science and technology in this century have found their expression in the language. Kannada which has grown as a vehicle of this modern thought is Modern Kannada. This modernization of Kannada is aresult of modernization of concepts of thoughts in its society. It is expected ultimately to replace English from all the spheres of life of Karnataka. The modernization movement in Kannada is traced to 1886 in the founding of Karnataka Bhaashoojiivini Sabha (Sridhar S.N 1991). If we compare Kannada as it is used today with the Kannada that is found in the records of the last part of 1800 AD, we can see systematic differences in phonology, morphology, derivational processes, word formation, syntax and discourse apart from the enormous growth of Kannada vocabulary.
Like any other living language, Kannada also has social and regional forms of speech called social dialects and regional dialects. Since it has a script of its own, it has both written and spoken forms. At the same time uniform text books, administrative documents, news papers, strong electronic media are used for communication . Due to this reason standard modern Kannada a preferable uniform umbrella form of the language , communicable to the people of all the regions and social groups in Karnataka, has grown. The properties of this variety of Kannada are discussed below.
4.4 Phonology
Kannada has 44 speech sounds. Among them 35 are consonants and 9 are vowels. The vowels are further classified into short vowels , long vowels and diphthongs.
4.5 Orthography
Kannada writing system is alpha syllabic. That is, basic consonant characters stand for consonant +/a/ and secondary symbols of vowels are added above, below or the right side of the consonant letter. Almost all the words used in Kannada including those borrowed from other languages like Sanskrit, Urdu, English etc., are Kannadised and made to fit into its structure. Thus, all words end with a vowel sound. For example:
kaar 'car' is kaaru.
manzuur 'sanction' is manjuuru.
4.6.0 Morphology
Basic morphological characteristics in consonance with the need of IL are presented in brief here.
4.6.1 Pronouns
Kannada has first person, second person and derived pronouns.
| First person singular | naanu | 'I' |
| First person plural | naavu | 'we' |
| Second person singular | niinu | 'you' |
| Second person plural | niivu | 'you'(pl) |
| Derived proximate pronouns | ivanu,ivalu,idu,ivaru,ivu | 'he, she, this,they,these' |
| Derived remote pronouns | avanu,avalu,avaru,adu,avu | 'he,she,they,that,those' |
| Derived interrogative pronouns | yaaru, yaavanu, yaavalu, yaavudu, yaavuvu, eenu,elli,estu,entaha | person(mas,fem), 'who, which,' 'which' sg., 'which' pl., 'what,where,how much,what sort of' |
4.6.2. Nouns
Kannada has simple, derived and compound nouns. Simple nouns are explained in the following schema:
4.6.2.1 Simple Kannada Nouns
The words mentioned in the parenthesis are examples for the specific nouns.
4.6.2.2 Derived Kannada Nouns
Kannada has nouns derived from nouns , numerals, adjectives, verbs , agentivisors etc.,because of development of prefixation as a derivational process, large number of nouns are coined for use in modern Kannada (Sridhar,S N 1990). For example : asahayaka 'helpless person', ahindu 'non Hindu', anivasi 'non resident', durbalake 'misuse', swasahaya 'self help', meeljaati 'upper caste', mumbadti 'promotion', etc.
4.6.2.3 Compound Nouns
There are two major types of compound nouns - Endocentric and Exocentric compound nouns. They are formed by combining two independent nouns. These compound nouns(CN) function as a single noun.The first stem functions as attribute and the second functions as head of the compound.In case of endocentric compound nouns,the CN expresses total meaning or combined meaning of the component nouns. Some of the types of component nouns identified in this group of CN are:
| Noun + Noun | dhuumakeetu | 'comet' |
| Adjective + Noun | uribisilu | 'hot sunlight' |
| Verb + Noun | hurikadale | 'fried gram' |
In the exocentric CN , the CN gives a meaning different from the meaning of the component of its components or,their combined meaning. Some of the exocentric CNs are:
| Noun + Noun | kaimara | 'hand post' |
| Verb + Noun | sidimaddu | 'explosive' |
Here also due to the process of modernization, hybrid compounds, loaned compounds, explicator compounds have come to use in Kannada (Sridhar, S. N. 1990).
| asruvaayu | 'tear gas' |
| kaalaraa rooga | 'Cholera' |
| tadeyaagne | 'stay order' |
| patrikaaghoosti | 'press conference' |
4.6.2.4 Gender
The gender distinction is based on whether an object belongs to the rational or irrational category. The rational group, capable of thought has masculine and feminine distinction which are biologically male and female respectively. But in plural, the distinction is unmarked. For example: vidyaarthi(mas) 'student', vidyaarthini(fem), 'student' vidyaarthigalu (pl) 'students'. The noun denoting the irrational object is neuter. Accordinglythe verb is also marked for masculine, feminine and neuter. For example: hoodanu (mas) 'he went', hoodalu (fem) 'she went', hooyitu (neu) 'it went'.
4.6.2.5 Number
Kannada nouns are inflected for number markers. Normally, the noun stem itself acts as a singular and the plural marker is added to the stem to convert it into plural. The three plural markers used are:- galu , - ru , - andiru Usually, - ru is added to rational nouns like,:huduga - ru = hudugaru 'boys'. adyaapaka - ru = adyapakaru 'teacher' (hon). Nouns like :pustaka - galu = pustakagalu , 'books'. granthaalaya - galu = granthaalayagalu , 'libraries' and the plural marker - andiru is added to the kinship terms like, - maava -andiru= maavandiru 'fathers in law' anna - andiru= annandiru 'brothers' Many rules governing the functioning of number in kannada too have exceptions. In modern Kannada swaami - galu 'swamis', mantri - galu 'ministers' are grammatical.
4.6.2.6 Case System
The syntactic and semantic functions of noun phrases are expressed primarily by case suffixes and post positions. The case markers are suffixes added to noun stems to indicate different relationships between the noun and other constituents of the sentence. They are added to pronouns also.
| Case | Marker |
| Nominative | -0(u,nu,lu,ru) |
| Accusative | -annu |
| Genetive | -a |
| Dative | -ge, -ige, -akke, -kke |
| Locative | -alli |
| Instrumental/Ablative | -inda |
| Vocative | -ee / vowel length |
The basic form of the noun as it occurs (un marked) as either the subject or predicate nominal in a sentence is in the nominative case. There are few exceptions where -u is suffixed mostly in writing. Chidanandamurthy (1984) opines that Kannada has no nominative case; the nominal base with its gender/number marker itself is used in the nominative. The other cases have clear markers and are same irrespective of gender and number, and are added to the noun stems after gender/number markers. Kannada has a set of 'post positions' added to the end of noun phrase usually after a case marker to indicate time, location, instrumentality etc (Schiffman 1979). Chidanandamurthy (1984) states that all cases are expressed through post positions and we have reasons to believe that the post positions which are mostly bound forms now, were free forms earlier. But certain post positions like mee:le 'above', eduru 'opposite', horage 'out side', munde 'in front' etc. function independently of NPs as adverbs.
4.6.3 Adjectives
The function of adjective is to qualify a noun. In Kannada, adjectives are classified into six groups. They are given below.
a. Dimension
ettara 'high'
taggu 'low'
udda 'long'
gidda 'short'
agala 'wide'
dappa 'thick'
telu 'thin'
b. Physical property
dodda 'big'
cikka 'small'
bisi 'hot'
tampu 'cold'
dundu 'round'
cappate 'flat'
ghatti 'hard'
medu 'soft'
c. Color
bili 'white'
kappu 'black'
kempu 'red'
niili 'blue'
hasiru 'green'
haladi 'yellow'
neerale 'purple'
gulabi 'pink'
d. Human propensity
koopa 'anger'
kurudu 'blind'
muugu 'dumb'
kivudu 'deaf'
priiti 'affection'
noovu 'pain'
e. Age
hosa 'new'
hale 'old'
ele 'tender'
mudi 'old'
hiri 'elderly'
kiri 'young'
f. Value
sari 'correct'
tappu 'wrong'
sulabha 'easy'
kastha 'difficult'
uttama 'good'
ayoogya 'bad'
4.6.3.1 Attributes
The words that are not pure adjectives but function as adjectives are identified as attributes. Some of them are derived from verbs. A few examples are as follows:
unnata 'higher'
pracalita 'current'
aadhaarita 'dependent'
nirnaayaka 'decisive'
4.6.4 Verbs
The person, number and gender features of the head noun of the subject NP determines the agreement marker of the verb. The verb is an obligatory constituent of a sentence except in copula dative constructions where it is optional. It can also be the only constituent in imperative and often in affirmative sentences. Verbs are usually at the end of the sentence and have post positions instead of prepositions since Kannada is 'Left branching language'. Thus adjectives, genitive and relative clauses precede their head nouns. The word order is Subject, Object, and Verb (SOV) unlike SVO order of English.
4.6.4.1 Tense
There are two tenses in Kannada. They are - Past and the non-past. The non-past denotes both present and future. However present, past and future tenses have different tense markers.
4.6.4.2 Mood
Mood is associated with statements of fact versus possibility, supposition, etc. Four moods expressed in Kannada are: infinitive, imperative, affirmative and negative. Additional modal forms are indicative, conditional, optative, potential, monitory and conjunctive.
4.6.4.3 Aspect
Adding iru 'to be' or some other aspect marker to the past participle of the verb followed by tense, mood and other markers indicates aspect. For example: ood - iru - tt - een -e to read - to be (in habitual sense) - person gender marker.
4.6.4.4 Voice
Verbs are divided into - active, passive, neuter and causal. The passive has two types - personal passive and impersonal passive. In case of personal passive, any transitive verb can be made passive where, underlying subjectbecomes an oblique object and receives the instrumental marking -inda. In case of impersonal passive, the subject is covert such as,yaroo. Causative suffix to verb is -isu.
4.6.5 Adverb
Some words like aaga, iiga ,indu 'then, now today' etc., function as adverbs. Adding -aagi 'having become' to the nouns and adjectives also forms adverbs. For example: santoosa - santoosavaagi 'happily - happiness.'
4.7 Structure
Chomsky treated the determiners 'a' indefinite and 'the' definite, as constituents of a Noun Phrase(NP) by a phrase structure rule. The NP in Kannada is simple and has adjectives derived from nouns or verbs and nouns of various sorts that take case endings and post positions. In some cases NP may contain pronouns, numerals, color terms, deictic particles such as 'this', 'that', 'which', etc., and quantifiers like 'many', 'some' etc. English indefinite determiner has a syntactic constraint that it occurs only before the noun and never after it. Where as in Kannada, it can both precede and follow. Also NP is a major constituent of a sentence that functions as an argument of the main verb of the sentence. It consists nominal head or pronoun and may be followed by modifiers. Syntactically NPs are identified by their potential to act as subjects, direct objects, indirect objects and compliment of postpositional phrases. As subjects they control verb agreement in person, number and gender and serve as sole antecedents of reflexives. They are marked for case and number.
The purpose of our present study is to identify only NPs because, the working purview is the title of the documents and the language is indexing language. It is a well-known fact that most of the expressive titles do not contain verbs. The noun variants of a verb is used in rendering the title of the document and further a title is given from one word to one phrase, metaphor, etc., instead of a complete sentence. Such noun variants of a verb is expressed either as 'energy' or 'action' in the analytico synthetic school of thought of IL adopted in the present study. Hence in indexing language, identifying NP is quite sufficient. This has been further discussed in Chapter Six (6.6.1)
While coining the subject headings in Kannada, all the above factors are taken into consideration. The next chapter deals with the development of Kannada and technical literature in it, which speculates the need for developing indexing language in Kannada.
*** *** ***
CHAPTER FIVE
TECHNICAL LITERATURE AND GLOSSARY IN KANNADA
| 5.0 | Introduction |
| 5.1 | Technical Literature |
| 5.1.1 | Literature Dominated by Sanskrit Terminology |
| 5.1.2 | Advent of Persian and Arabic Terminology |
| 5.1.3 | Arrival of English Education and Terminology |
| 5.1.3.1 | Administration |
| 5.1.3.2 | Education |
| 5.1.4 | Planned Development of Kannada |
| 5.1.4.1 | Administration |
| 5.1.4.2 | Education |
| 5.2 | Standardization of Technical Terms |
| 5.3 | Principles Used in the Preparation of Glossaries in Kannada |
| 5.3.2 | Compilation of Technical Glossaries Through Word Frequency Count |
| 5.3.2.1 | Sample Data |
| 5.3.2.2 | Observations |
| 5.3.2.3 | Coining of New Word on Indigenous Grammars |
| 5.3.2.4 | Grammatical Aspects and Technical Glossary |
| 5.4 | Conclusion |
5.0 Introduction
This chapter deals with the availability of technical literature, coining of technical terms and preparation of a sample monolingual glossary on education in Kannada.
Languages develop in the course of their existence through the addition of: new vocabulary, styles of presentation of information, discourse patterns necessitated by the new functions and demands on language. Language development is recognized as natural as well as planned process. Kannada has undergone both of them.
5.1 Technical Literature
The historians of Kannada literature have elaborately debated as to 'What constitutes technical literature in Kannada?' It includes : technical literature relating to literature itself such as alankaara (rhetoric) ,chandassu (prosody), vyaakarana (grammar), nighantu (dictionary), gnaanakoosha (encyclopedia); religious technical texts and laukika (worldly,general) technical texts, like the ones regarding medicine, astrology, mathematics, chemistry, music etc (Seetharamaiah 1975). But in the context of industrialized, technological societies, literature relating to general sciences, social sciences and technology is termed as technical literature.From the point of view of language ,four distinct phases are visible in the development of technical literature in Kannada.
- Literature dominated by Sanskrit terminology
- Advent of Persian and Arabic terminology.
- Arrival of English education and terminology
- Planned overall development of Kannada since independence and reorganization of states.
5.1.1 Literature Dominated by Sanskrit Terminology
Kannada has a history of nearly two thousand years. Ashoka's 'Brahmagiri inscription' of 250 A.D and 'Halmidi inscription' of 450 A.D are the first instances of the presence of written form of Kannada. Attempts to codify Kannada with the help of dictionaries , grammars and manuals of language usage have been made by scholars from time to time. The first available Kannada work produced nearly eleven centuries ago around 860 A.D is 'kaviraaja maarga' - is a manual for poets on rhetoric, and is also a technical work (Srikantaia 1973). kaavyavalokana by 3rd Nagavarma of 1050 A D , udayaadityalankara by Udayaditya (?) of approximately 1150 A D, chandoombudi by Nagavarma 1 (?) of approximately 990 A D , chandonushaasana by Jayakiirthi of 11th century are some of the important works of rhetoric and prosody. The earliest Kannada dictionary Ranna Kaanda was compiled in 10th century . This is the first known dictionary in the language. shabdasmruti by Third Nagavarma of 1050 A D, abhidaana vastukoosha by Second Nagavarma approximately of 1050 A D followed . The earliest first full fledged grammar of Kannada - Shabdamanidarpana is by Keshiraja of approximately 1260 A D. Many more classical works followed these.
In the category of worldly / general sciences, works have been compiled on medicine, treatment for poison, medicine for women, children, wounds, elephants, horses, cattle, etc. And also works have been compiled on cooking, mathematics, astrology, etc.
5.1.2 Advent of Persian and Arabic Terminology
Along with the change in the rulers, Kannada came into contact with their languages also. The regions where Kannada was spoken were ruled by the Muslim kings. The earliest appearance of Arabic terms is traced to 1398 A.D. in Mangaraja Nighantu. But, from 16th century onwards the quantity of vocabulary from these languages in Kannada shows a marked increase. The major influence of Arabic and Persian and the beginning of infiltration of terminologies from these languages is traced to the period of Vijayanagara kings. Naturally, in due course they found their way into revenue, administrative, legal documents etc (Kedilaya 1970).
5.1.3 Arrival of English Education and Terminology
English entered India around 1748 A D. Along with the Britishers , Kannada came into contact with their language - English. The work of Kannada by westerners began as a part of their attempt to spread Christianity. However their contribution is recognized as most important attempt to develop Kannada. Some of the important dictionaries produced by them are : A Dictionary, Carnataca and English (1832) by Rev.William Reeve; A Dictionary, Carnataca and English (1845) by Rev. John Garret ; A Dictionary : Canarese and English (1858) by D. Sanderson; English - Kannada Sala Nighantu (1876) by Rev. F.Ziegler; English - Kanarese Dictionary (1888) by F.Ziegler; Kannada - English Dictionary by Rev.F.Kittel (1894) and Kannada - English School Dictionary by Rev.J.Bucher (1899). Some of the important grammars by them are : Grammar of the Kurnata Language by W.Carey (1817); A Grammar of the Carnataka Language by John Mckerrel (1820); Elementary Grammar of the Kannada or the Canarese Language by T. Hodson (1859); Kannada Sala Vyakarana by F.Ziegler (1866)
5.1.3.1 Administration
The Britishers recognized the need to communicate in the peoples language. The major Acts and rules of administration prepared by them for all India purposes were invariably translated into Kannada and made available in the offices (Banakara 1986). The literature developed during their period relating to administration was mainly translation oriented one from English.
5.1.3.2 Education
With the result of industrial revolution of Europe, educational institutions introduced English and modern development in Science and Technology. In order to propagate Christianity, many missionaries opened educational institutions also. In addition to this, few institutions like, Hindu college in Calcutta, Deccan college at Pune and Urdu college at Delhi also came into existence. These opened a new world of knowledge to those who aspired for it. For the first time the printing press was established by John Hands in Bellary in 1827 to print in Kannada. This gave a fillip to spread of education. The importance of education in Kannada was realized by persons like Walter Eliot who started a Kannada school in 1831 in Mumbai - Karnataka, and ran it for three years till 1833. Samuel Hebberk opened a Kannada school in 1836 in Mangalore. The Mumbai government in 1836 took a decision that since Kannada is the language of the people of Southern Maratha, both administration and education should be conducted in it only. The Mysore Government was providing finances to Wesleyan Mission for promoting education . As a result, Kannada schools were opened in 1842 and 1846 in Tumkur and Shivmogga districts respectively. Bowring's report on educational reforms 1868, recommended the opening of Kannada schools in every hobli and teaching subjects through Kannada only. In pursuance of implementation of this report, remarkable progress was seen in Kannada education in 1879 (Banakar 1986). Though Kannada was made the subject for Master of Arts(M.A.) in 1901, it is only in 1912 one person did Kannada M.A. In orderto impart Kannada education and render education through kannada, textbooks and reference works were prepared. The terminology required to render the texts from English to Kannada was acquired mainly through transliteration and to certain extent through translation using Sanskrit and Kannada sources.
5.1.4 Planned Development of Kannada
The Constitution of India promulgated in January 1956, vide Article 345 made provision for a state to adopt one or more languages for use in the state for all or any of the official purposes of it. Karnataka state with majority of Kannada speakers was formed while reorganizing the states on the basis of language on November 1, 1956. Kannada is also one of the 18 languages included in the VIII Schedule of the Constitution. In continuation of this, the Karnataka Official Language Act 1963 was gezzeted on October 10 ,1963. The functional load on language increased enormously. So, from this point onwards, systematic language development activities were takenup to make Kannada as a vehicle of modern thought by using it as a language in education, medium of instruction at as many levels as possible, administration and mass communication.
The Kannada Sahitya Parishat,Bangalore conducted a workshop in 1977 to prepare a blue print for the development of Kannada.Many scholars in Kannada contributed to this workshop and elucidated the steps to be taken for creating creative literature, writing for science, humanities, text-books, newspapers, translation from other languages into Kannada and from Kannada to other languages, research, documentation and furthering of folklore, archaeology, arts and crafts (KSP 1977).Idea behind this workshop was to develop Kannada in its totality. Setting up of the Kannada Development Authority in 1991 , Kannada University in 1992 , and Karnataka Book Authority 1992 are the major land marks in the planned development of Kannada. Major task of language development involved creation/finding of technical terms to fulfill the new needs. Technical terms are the "...word or word groups used to name a notion , characteristic of some special field of knowledge."(Singh 1982)
5.1.4.1 Administration
Due to the efforts of Committees and the individual scholars important and necessary legal references for administration like Constitution , Criminal Procedure Code, Evidence Act,etc, are published. So far more than 174 Central Acts, 72 State Acts, English - Kannada legal glossary are available in Kannada. Also select Judgments are translated into Kannada and published every month in special Kannada Law Journal.
5.1.4.2 Education
In Karnataka, Kannada is taught as mother tongue and other tongue. It is also a medium of instruction: for all subjects up to 10th standard; in the pre degree and degree classes for some selected science subjects; and all the subjects of the humanities group. In these classes, among the professional courses only agricultural science is taught through Kannada. At the postgraduate level only humanities subjects are taught through Kannada.
The Official Language Resolution 1968, adopted by both Houses of the Parliament asked for the full development of the languages of the VIII Schedule and that
...a program shall be prepared and implemented by the Government of India in collaboration with the State Governments for the coordinated development of all the languages . so that they grow rapidly in richness and become effective means of communicating modern knowledge.
So, in order to provide Kannada textbooks at the university level, universities in Karnataka took up the task.
The Mysore University organized two important workshops to create scientific literature in Kannada in 1971 and 1975: Vijnana Sahitya Nirmaana and Saastra Sahitya Nirmaana respectively . These workshops were held to help the authors to write Science books in Kannada and also design the teaching methodology for science in Kannada in class rooms. Scholars from all spheres of Science contributed to the workshop.In preparing the text books in Science, the major problem was that of 'technical terms'. It is agreed fact that, in the initial stages scientists used Latin and Greek. For example Newton used Latin. We may say here that, the present position of Kannada in Karnataka was the position of English, French, German etc. up to the end of the 17th century. They all realized that, unless the science documents are made available in their own language, which could be understood by and large, the total development cannot be achieved.In the process of creating technical terminologies, many words were retained since, even those terms were coined with more than one language. In some cases the word stem were retained from Greek and Latin and added prefix and suffixes.
The development of the discipline and language go parallel. Scientific and technical terms need definitions and they stand and represent only that. But non technical terms are not so. They are flexible. It is not possible to get ready made terms. The scientific growth is so fast that it is difficult to keep a check over it. Depending on that, as far as possible, one should coin the terms in Kannada or else borrow the terms as they exist in the source language. It depends upon the total environment also. Few Kannada words do not have English equivalents and vice versa. For example: pance, lungi, navane, sajje, gojju etc. oats, bread, cheese, coat, shoes etc. Keeping all this in mind and other practical problems in devising the terms, the workshops advised that 80% of the technical terms used in English can be used in Kannada.
Example: FOSSIL.
One termed it as faasilu in Kannada. Another termed it as paliyulike. Objection was raised to this, since fossil was not a past remain, but the remain of a being with life, hence recommended jiivyavasesa. It went on up to diirgakalada hinde jiivisidda jiiviya avasesa. One commented that only a sentence can represent the word fossil. If the word fossil is retained fossilization can be termed as faasiliikarana etc. Keeping both the views (1) retaining English words and (2) Sanskritization, scientists tried to formulate technical terms and designed text books.
Up to March 1987, 785 books were prepared in which 593 were supposed to be original writings and 192 translations. Among these 376 titles were recommended for prescription in the syllabus [Dalal :1987] . In addition to this institutional effort, the practicing teachers also have contributed books for different subjects .In 1965 there were 1332 Secondary schools with Kannnada medium. The same increased by three fold and became 3945 in 1986 (NCERT 1986 -91). In the secondary schools and pre degree courses Kannada medium students outnumber English medium students .Even in the competitive examinations under the control of the state, Kannada medium applicants out number English medium ones. The Karnataka Public Service Commission conducted examinations for clerical cadre posts in 1986.Out of 1,42,000 applicants for second division clerk's posts 1,28,000 opted for Kannada medium. Only 18,929 applicants opted for English medium. During the same year for the posts of first division clerks 46,324 applicants were there. Among them 33,500 choose Kannada medium and 12,824 choose English medium. In the gazetted probationers examination during 1993 out of about 25,000 applicants, 15,000 opted for Kannada medium and 10,000 for English medium (Mallikarjun 1995).
5.2 Standardization of Technical Terms
The Commission For Scientific and Technical Terminology (CSTT) serves as a policy making body for medium switch over and translation agency, coordinates the terminology evolved, and considers the translation of books from one language to another . The CSTT was constituted by the Ministry of Education,Government of India in 1961. Preparation of glossaries in Indian languages, Scientific and technical dictionaries, standard scientific text books translated to Indian languages are some of its functions assigned to it.
The principles formulated for the evolution of terminology are as follows:
- International terms have to be retained as such and only their transliterations have to be given.
- Pan-Indian equivalents have to be coined from Sanskrit basis.
- Indian languages are free to use current word in their own languages to their Sanskrit equivalents on account of their common usage.
In order to build the technical vocabulary in Indian languages, the following linguistic devices were suggested by the CSTT.
- Indigenous Sources: The terminologies in basic Social Sciences and Humanities has a long tradition in India particularly, the terms pertaining to Philosophy, Astronomy, Mathematics, Aesthetics, Poetics, Linguistics and Literary Criticism. They have come mainly from Sanskrit literature and constitutes tatsama and tadbhava of the Indian vocabulary. medicine = ausadha, equator = bhuumadhya reekhe, longitude = rekhamsa. Likewise, many terminologies pertaining to administration, law, revenue, politics, architecture and commerce have come from the Perso-Arabic that has characterized the language of governance during the Moghul period. " In a process of sociolinguistic fusion, this vocabulary got assimilated in the Indian languages over a period of time and in the North where its impact was the strongest, it marked the emergence of a style called Hindusthaani which provided equivalents that were in actual use in professional transactions." (Singh,S 1994). In the Administrative glossaries in Indian languages, many terms have been borrowed from Hindustaani. Sum = rakhamu, forfeiture = japti. Among the regional languages, many of them were rich in some specialized domains of profession. Article 351 of the Indian Constitution provides that Hindi should assimilate vocabulary from the Indian languages so that, it becomes an effective representative of the composite Indian culture. Hence many words from Indian languages were adopted as equivalents for English terms.
- Loan words: Terms based on proper nouns, binomials and words that has become an intrinsic part of the Indian vocabulary has come under this category. Bonus , gelatin, academy, etc.
- Innovation : New terms has to be coined or innovated where correct equivalents are not available for English terms by assigning a new meaning to a word already in use , enlarging the semantic potentiality and also by coining a completely new term by means of the usual word formation devices such as suffixation, prefixation and combinations. In Hindi such terms are mostly on Sanskrit matrix and in other Indian languages, it was both on Sanskrit and Hindi matrices. In that way many Hindi words have been Kannadised in the process of terminology creation especially in 'Administration glossary'.
- Translation equivalence : The accepted principle in this is that the sense of the term should be translated rather than its literal meaning.
- Standardization : Standardization and social acceptability of a new terminology are dependent on the exposure and currency that it has received in the communication network of concerned domains. The linguistic requirement of a technical equivalent is that it must be fertile enough to generate maximum possible derivatives and combinations under accepted grammatical system of the language. Example : Airplane which means havaayi jahaju is translated as vimaana so that the terms such as - vaimaanika, vimaana caalaka, vimaana caalane, etc. could be derived. In the process of coining the subject headings also the principles introduced in coining the technical terms by the CSTT are quite appropriate and worth adopting.
The CSTT covered all domains and disciplines of Science, Social Sciences, Humanities, Medicine, Engineering, Agriculture,etc. in coining the technical terminologies. The State Language Institutes took over the responsibility of the evolution of technical terminology following the guidelines and models evolved by the CSTT.
5.3 Principles Used in the Preparation of Glossaries in Kannada
In preparing the glossary , following steps may be referred as important steps. The preparation of a glossary primarily depends upon its purpose,aims and objectives. Depending upon that,the methodology also differs glossary to glossary. Mentioned below is the example for methodology in preparing an agricultural glossary which is dependent on the agricultural occupation in villages of Karnataka.
- Preparing a primary list of words using published documents and mass media.
- Selecting relevant terms from the above list and alphabetizing.
- Preparing the questionnaire for the field work.
The questionnaire is accompanied with the primary list of words. Some of the problems that may arise in the process are:
- The terms that are used in different rural areas may differ from the written variety.
- The pronunciation of some words differ region to region.
- The meaning that is already listed in the published dictionary may also vary.
- To give the meaning of certain words are so difficult that,it can be identified, but at the same time to express it may be difficult, etc.
The whole glossary is classified under the following concepts related to agriculture:-
| Instruments | upakaranagalu |
| Plants | belegalu |
| Different levels | vividha hantagalu |
| Irrigation system | niiraavari vidhana |
| Diseases | roogagalu |
| Gods and folk belief | devaru mathu nambikegalu |
| Customs | aacharanegalu |
| Soil varieties | mannina bagegalu |
| Economics | aarthica nelegalu |
On the basis of the above classification, the collected words are grouped.The arrangement is alphabetical within the classified categories. Against each word - its pronunciation , geographic region (where it is used) meaning,etc., are given.Some words that cannot be literally expressed are explained by providing relevant pictures.Previously,depending upon the person's occupation,the equipments required for the occupation and the knowledge about it were under his control. But now, modernization has brought many changes , making the whole occupation mechanized and at the same time bringing the knowledge to the information zone. The primary job of a occupational glossary is to list the terms that are relevant to the particular occupation.
5.3.1 Compilation of Technical Glossaries through Word Frequency count
One more helpful method in compilation of glossaries is the word frequency count (WFC) method. "Creation of subject glossaries can be simplified by WFC studies"(Sharada 1994). In the present chapter, an experiment is done using the kannada titles in Siksana 'Education'.
5.3.1.1 Sample data
From the Granthaloka journal,two hundred and seventy (270) titles were collected listed under the heading siksana. In order to get the alphabetical list of each concepts used in the titles and check their frequency of their occurrence,the relevant software was CDS/ISIS (1.3.2.4). Stop word file was created in order to control the structure words. The alphabetical list consisted of 330 content words. The total number of postings of these words were 1372. In addition to the enumerative study, the methodology of word frequency study is of immense help in glossary creation with the automatically indexed concepts. Appendix I depicts the sample technical glossary in Kannada.
5.3.1.2 Observations
It was stated in one of the earlier study done on WFC (Sharada 1994), that , while counting the frequency of occurrence, the word roots could be taken into account neglecting the inflections, because of less difference in meaning of derived words. That was similar to the system of 'head words' developed by Palmer, whose work in the institute for Research in English Teaching, Tokyo (Tokyo Report 1930-31) has been accepted by many researchers in this field. But in the present experiment, it cannot be accepted without modification because of the contextual semantic interpretation. For example:
PARI$ This command in CDS/ISIS - Search terminology displays the following words:
PARI PARICHAYA
PARIHAARA
PARIIKSHE
PARISARA
PARISHAT
PARIYA
Though one or two letters are added to the word `PARI', the meaning is different in each context. In few exceptional cases Palmer's principle could be adopted wherein the morphological inflection will not semantically harm the root word. For example:
| SAALE$ | SAALEGALALLI | SAALEGALU | SAALEGE | SAALEYA |
| SIKSANA$ | SIKSANAKKE | SIKSANAKRAMA | SIKSANADA | SIKSANADALLI |
This experiment also depicted many interesting factors such as, words from ancient and medieval Kannada.Few vocabularies are retained and few are changed. Most of the words have Sanskrit origin, later on kannadised. For example:
| Ancient | Medieval | Modern |
| gurukula | same | not in use |
| kseetra | same | same |
| not in use | taaynudi | maatrubhaase |
| vidyaapiitha | vidyaakendra | vidyaalaya |
| adhyayana | same, vyaasanga | oodu |
| sisu | same | makkalu |
From the above example we may see that, in the medieval period the influence of Tamil on Kannada - taaymozhi has become taaynudi. But in the modern Kannada again Sanskrit originated maatrubhaase is used. After consulting the technical terms glossaries, subject dictionaries and also the experts in the field many terms have to be standardized before it enters attributes of IL.
5.3.1.3 Coining of New Words Based on Indigenous Grammars
It seems relevant to refer to the principles adopted in coining new words in Indian languages based on indigenous grammar. To develop the internal resource of the language, one technique is, adding indiclinables, some of which will not have its own meaning but add meaning to their head word. For example:
HAARA
PRAHAARA
PARIHAARA
NIRAAHAARA
AAHAARA
SAMHAARA
In addition to the above techniques of prefixation, suffixation , in kannada the words are borrowed and are still in currency. This holds good for most of the Indian languages. In Manak Hindi Kosh we get plenty of examples.
In coining the new words while preparing the technical glossary, the order of reference to language terminologies will be,Sanskrit - Hindi - Indian Languages.
This is the reason we find many Hindi and Sanskrit coinage in technical glossaries.
5.3.1.4 Grammatical aspects and Technical Glossary
A glossary or dictionary can be scientifically prepared based on the linguistic principles. The statement bhasaasaastra drustiya kade viseesa gamanavannu harisalaagide (Special interest has been shown towards linguistic principles )is mentioned in 'kannada nighantu' (KSP1970)
The basic objective of the above experiment was to compile a sample glossary . Hence the alphabetical list of content words were subjected to analysis. While entering the data ,the document titles were entered without any change. As a result, the words got indexed with the formal grammatical markers. Syntax play a very important role in glossary preparation. Uniformity has to be maintained while rendering the technical terms in the glossary. While delinking the syntactic markers it should not semantically affect the terms. For example :The word aacharaneyalli 'in practice' has been indexed with the locative case marker -alli which has to be delinked and the word aachrane 'practice' has to be entered in the glossary.In the word aadhaaragalu 'supports' the plural marker - galu has to be delinked and only aadhaara 'support' has to be considered. The notion behind the above statements are that, the terms in a glossary are rendered in nominative case and singular number. As mentioned in [5.3.2.2], Palmers root word principle may be adopted in cases like, bodhaneya, bodhanaa, bodhaneyalli, bodhanegeetc the word bodhane 'teaching' can be taken as the headword in the glossary.
The borrowing of loan words principle could be applied in words like ganaka, which is well known as computer, the word junior is retained in the word juuniar kaaleeju and the word college is kannadised using the affix u. The second observation in this word is , though the term in a glossary is single term representation, in few cases compound terms have to be used to give complete meaning. Hence the words juuniar and kaaleeju cannot be seperated but entered as a compound word.
So far, technical glossaries are available in different disciplines from English to Kannada entitled 'paaribhaasika padakoosa' published by Department of Kannada and Culture Bangalore.In the present study,a trial is made to prepare monolingual kannada glossary. Here, dialect form is not rendered. Instead the words are ended either with the letter e or a. The arrangement of words in the glossary is according to Kannada alphabetical order. Compared to English alphabetisation in Kannada is bit difficult because of clusters. Such letters are put at the end of each letter. The order followed is, just after the word the parts of speech is given in parenthesis in the abbreviated form. .Example (naa) for naamapada (Noun Phrase).
5.4 Conclusion
As far as the importance of Kannada is concerned,few technical courses in the state - certificate course in library science etc., are taught in Kannada. Even technical course in industrial training is undertaken in Kannada all over the state. Except for the technical terms, they are using Kannada as the medium of instruction (Krishna Bhat 1985). Many Universities in the state encourage students to take Kannada medium both at undergraduate and postgraduate levels. Most of the Universities has permitted writing Doctoral theses in Kannada for selected subjects. For example Bangalore University permitted for the first time three candidates - one in History and two in social work (The Hindu 28-8-1990). The reason behind is, that the candidate from rural areas and those studying in Kannada medium should not be deprived of the right to pursue higher studies in their regional language.
While discussing library function, Seshagiri Rao (1985) states that the love towards English is so much that even the library membership card, due date slip, issue details etc. are all will be in English. He urges the government to put an end to this type of usage because, rural public depend upon somebody who knows English for using the library in their region. Few libraries in Karnataka now have adopted Kannada for printing library membership card. For example Maharani`s Women`s College of Mysore.
The public libraries started in Karnataka in 1968 under the Public library Act are - one central public library, 15 state central libraries, 20 district central libraries, 334 divisional public libraries, 167 library service centers and 551 mandal libraries, 1922 Rajaram Mohan Roy depository centers, 11 mobile libraries in total 3321 public libraries in Karnataka (Prajavani 4.1.1994).The library staff who have studied in Kannada medium from the beginning and done the course in library science in Kannada medium only find it difficult to use the library classification schedule which is available only in English. Even the number of books published in Kannada in all spheres of life has increased. So is the importance of Kannada in Karnataka. The sample glossary of education presented here will help in developing the attributes of IL.
*** *** ***
CHAPTER SIX
RULES FOR GENERATING SUBJECT - HEADINGS:
PRE - COORDINATE INDEXING
| 6.0 | Introduction |
| 6.1 | Subject Headings |
| 6.2 | Thesaurus |
| 6.2.1 | Procedures for Development of S H |
| 6.2.1.1 | Vocabulary Control |
| 6.2.1.1.1 | Word Combinations |
| 6.2.1.1.2 | Word Form |
| 6.2.1.2 | Relationship Between Terms |
| 6.2.1.3 | Management: Including Editorial Control and Form of Output |
| 6.3 | Selection of Descriptors |
| 6.4 | Systematic Arrangement of Subjects |
| 6.4.1 | Universe of Subjects: Arrangement of Main Subjects |
| 6.4.1.1 | Principle of Increasing Concreteness |
| 6.4.1.2 | Principle of Increasing Artificiality |
| 6.4.1.3 | Partial Comprehension |
| 6.4.1.4 | Fused Main Subjects |
| 6.4.2 | Arrangement Within Facets |
| 6.4.2.1 | Chronologist |
| 6.4.2.2 | Evolutionary |
| 6.4.2.3 | Increasing Complexity |
| 6.4.2.4 | Size |
| 6.4.2.5 | Preferred Category |
| 6.4.2.6 | Citation Order |
| 6.5 | Models of Indexing Systems |
| 6.5.1 | Authority Lists Based Subject Indexing |
| 6.5.2 | Subject - Chain (Hierarchy) Based Indexing |
| 6.5.2.1 | PRECIS |
| 6.5.3 | Unit - Term (Post-coordinate Indexing) |
| 6.6 | Recent Developments in Indexing |
| 6.6.1 | Frame Based Knowledge Representation |
| 6.7 | Conclusion |
6.0 Introduction
Language lexicon or glossaries are the main component of a NL. In IL the same is the list of subject headings (SH).
6.1 Subject Headings
The intellectual organization of information represented through SH, surrogates the macro and micro conceptual organization of an idea in the text. The SH is a term or set of terms used to surrogate the concepts for an entity, property, action, space and time and other kindred objects. The word 'Term' in NL is the lexical item , a single term may be represented in different context with different meanings. Where as,SH provides the precise role of the same term in one single context. It is sharp and equal to summarized text. Hence SH is the principle basis on which the information is retrieved from the system. The flexibility or the richness and variety of the terminology used in NL causes problems in information processing and retrieval. To overcome this problem, terminological control, either in indexing or searching are required. Reference of entities related to one concept should be collocated in one place in the file and not scattered in many places. This may be the reason for Roget to state that the closest approach to a thesaurus construction is faceted classification (Fosket 1981). These unique concept identifiers may be created from scratch or selected from spelling variants, synonyms, quasi synonyms etc., referring to the concept. Because the problems in retrieval include spelling variants, synonyms, quasi- synonyms etc. Few steps have to be taken to reduce the list to manageable set of concepts without loss of content through consolidating synonyms - quasi synonyms, singular - plural and other morphological and spelling variants, etc.
6.2 Thesaurus
A controlled vocabulary contains a unique term for each meaning of homonyms. Such a list of terms showing their classification according to the ideas they represent is called a thesaurus. In contrast to a dictionary which provides definitions for given words or terms, a thesaurus provides words or terms to express meanings that are implied by the term relationships given in the thesaurus. Thesaurus may be arranged alphabetically and used to construct an index. But, it is not an index itself since it does not consist of locators for items in the collection. A thesaurus classifies terms by arranging them in hierarchical classes, which shows relations necessary for indexing and retrieval according to the information needs of the users.
Since the present study concentrates on the methodology for preparing subject headings in Kannada with the following hierarchical structure of the thesaurus, it has been thought appropriate to adopt the methodologies that are followed in the thesaurus construction for precoordinate indexing.
6.2.1 Procedures for development of SH
Several studies have been undertaken in developing methods for generating subject headings. To mention few - Vickery (1953), Moers(1963), Borko (1965), Gopinath (1992), Austin(1987),Bhattacharya(1979), etc. Some of the thesaurus based precoordinate systems are POPSI, PRECIS, NEPHIS etc.
To govern the generation and rendering of subject headings, there are standards such as BSO and ISO. Even PRECIS thesaurus is based upon a set of procedures and basic relationships described in the International Standard on thesaurus construction (ISO 2788) which deals with three main aspects of thesaurus construction.
- Vocabulary control
- Relationship between terms
- Management including editorial control and form of output
6.2.1.1 Vocabulary Control
The vocabulary control aspect deals with descriptors that consists of one or more words. As a general rule, the descriptor reflects the terminology of the subject irrespective of the number of words required to denote the concept. At the same time, it is desirable that it should contain as few words as possible and preferably only one.The compound descriptors should be entered in their NL order avoiding the use of abbreviations just to safe guard the clarity.
6.2.1.1.1 Word Combinations
In order to keep the number of descriptors within limits, the concepts are to be combined in some cases. In combining the concepts, as a general rule, there are two possibilities:
- Morphological factoring
- Semantic factoring
In the precoordinate indexing, the concepts have to be combined before they enter the system. Precombined descriptors should always be used when:
- The meanings of the simple descriptors on their own differ from their meaning in the precombined descriptor. Example: kai mara 'railway signal post;' benkipottana 'match box'
- The simple descriptors are used in hierarchical connections other than the precombined descriptors. Example: maulya maapana 'evaluation'
6.2.1.1.2 Word form
Once it has been decided to include a given descriptor in the list of SH or authority list, following are the few aspects that have to be taken into consideration to ensure that, it conveys the intended meaning as accurately as possible. The following are some of the aspects that have to be considered.
a. Spelling
The most widely accepted spelling of the word should be adopted. While formulating the rules for Kannada spelling system, 'Kannadashaili kaipidi'(Kannada Style Manual)(KSM) states that,
- Throughout a document one form of spelling should be used if there are more than one spelling for a word. Example: bareha - baraha 'writing'
- In case of words where they are pronounced same but written with two different spellings, the form which is more nearer to the pronunciation can preferably be used. Example : suurya ( - ) 'sun,' paryaaya ( - ) 'alternative, 'the former is preferred form.
- The words in which the use of unaspirated form instead of aspirated one which does not bring out a change in meaning can be used. If there is a meaning difference only appropriate form has to be used. Example : kathe - kate, 'story,' dana 'cattle', dhana 'money.'
b. Translation
Many current technical terms in Kannada have arisen by translation from both foreign and other Indian languages. Some words are Kannadized depending upon the suitability.
c. Transliteration
Most of the words which are in use in English but borrowed from other languages like, Latin, Dutch, German, etc., are in more currency in Indian languages also than the translated versions. Those terms have to be transliterated. As per the ISO 2788 rule, the transliteration which does not employ diacritical marks should be selected. Example: Sputnik, Satellite.Organic nomenclature,microorganisms,codes for agency names,etc., have to be retained as they are.
In Kannada so far the individuals were transliterating the borrowed words as they perceive their pronunciation. However the KSM in order to make Kannada communicable, prefers uniformity in transliterating words borrowed from other languages. The letter that is infrequently used is not preferred to the letter that is frequently used. Example : - 'English' preferred form is the latter one.
In some areas the word 'bank' is written as , , , . The preferred form is .
If the words borrowed from Persian or Arabic origin have to be transliterated they need diacritical marks. Example: But these are Kannadized and written without any diacritical marks.
d. Noun form
Descriptors should be preferably in the noun or noun phrase (NP) form. Adjectives, verbs and gerunds also have to be converted into NP. Since adjectives/attributes can be precoordinated with NP and taken as a compound descriptor, the choice to enter them separately should be dictated by consideration of practicability and flexibility. Precoordination is recommended whenever a modifier appears very frequently in combination with a particular term.
e. Number
The ISO 2788 states that it is necessary to establish and follow national standards to decide that the representation of descriptors should be rendered in singular or plural. At the national level the only IL, `colon classification' follows singular representation. If the singular and plural forms of a word denotes a different meaning, both should be entered.
In English, in general, the plural form should be used for descriptors, particularly descriptors denoting the classes of things. The singular form is used for specific material or attributes, proper names and process terms. In Kannada, descriptors can be singular and in exceptional cases plural. A small number of nouns like anna(cooked rice), niiru (water),haalu (milk), etc are always singular since they are mass nouns.
f. Homonyms
The different meanings of homonyms must be marked and if any qualifiers are available, they have to be mentioned in parenthesis as part of the descriptor.
Example: kaalu a. leg, b. quarter, c. letter, d. ear stud.
In the above homonyms (a) could be used as it is. (b) could be used as an adjective quantifier, (c) could be replaced by the term patra and the present one deleted and (d) used as it is. In this manner each homonym that we come across while collecting the SH have to be tested individually. If both terms are used 'see' entry has to be given and also a scope note which is a brief explanation of the intended use of a descriptor may accompany the descriptor to terms which are in common use in different disciplines.
Morphology - maatasaastra or ruupasaastra in Medicine.
Morphology - aakrtimaa vinaana or ruupimaa vinaana in Linguistics.
Phonology - dani saastra in Medicine, dhvani saastrra or dhvanima vinaana in Linguistics.
The term dani is the synonym of dhwani. In order to standardize the terminology, synonyms dictionary has to be referred. Such a dictionary in Kannada is 'Kannada samaanaarta koosa.
6.2.1.2 Relationship Between Terms
The interrelations of one descriptor to other descriptor provides a kind of definition by placing the descriptor into the semantic space. Until now three types of interrelationships are recommended in the ISO:2788. They are:
- Hierarchical relationship
- Equivalence relationship
- Associative relationship
Hierarchical relationship:This is BT/NT relationship, which involves
- generic - both true and quasi generic relationship
- hierarchical whole - part relationship
- instance relationship
The perception of a quasi - generic relationship is likely to vary with subject field. Based on the whole - part relationship four classes of concepts can be organized into logical hierarchies. For example:
Geographical regions
Asia
South Asia
India
Karnataka
Mysore
Systems and Organs of the Body
Nerves system
Central nervous system
Brain
Hierarchical social structure
Dioceses
Parishes
Disciplines or areas of Discourse
Science
Biology
Botany
Equivalence relationship : This is also known as Use/Use for relationship. In the context of synonyms one of them should be chosen as the preferred terms which is hence forth consistently assigned to that topic. In PRECIS the non preferred terms are not written as components but printed as source terms in `See' reference that guides the users to their preferred equivalents.
Associative relationship : This is related term relationship or RT.
6.2.1.3 Management : Including Editorial Control and Form of Output
The IL so prepared should be updated continuously on the basis of the questions such as,
- Whether the proposed IL meets the requirements?
- Whether the selected descriptors are useful for indexing and retrieval?
- In which areas further disciplines are required?
- Whether the established concept relationships are correct and sufficient?
In order to fulfill the above requirements, a central authority should be nominated and charged with the responsibility of updating the IL time to time according to the defined procedure. It is also necessary to test during indexing or retrieval. If it is found that concepts or concept relationships have not been established with sufficient precision in the SH, new descriptors have to be established. New additions should be introduced in batches while revising the editions. In the computerized environment of precoordinate index such as PRECIS, descriptors will be automatically added.
6.3 Selection of Descriptors
The SH are collected in the following way by man or machine.
Sources for term collection may be:
- Subject specialists and potential users.
- Standard technical dictionaries and glossaries.
- Existing classification schemes and thesaurus.
- Nomenclatures.
- Indexing and abstracting services.
- Terms extracted from the text books,handbooks,title of the documents or abstract of a document without any vocabulary control.
- Terms extracted from the text or abstract of a document with vocabulary control.
- Terms which may not directly form part of a title but are equivalent to what is given in vocabulary control.
In the task of building the subject heading, high level users and specialists in the subject field are very important. After getting them together, brain storm them to list out terms that they use , read and search often. A descriptor bank is ready. The users vocabulary has to be standardized into system's searching by using terms from standards given by BSI. Later scan the technical literature in the field. From this we get, cluster of terms, the frequency of occurring of terms and other terms , ambiguities in the terminology and new terms just emerging in. The basic requirement of an IL is a complete vocabulary of sought terms including all necessary synonyms that are used in the indexing of a set of document.
Once the process of selection of descriptors and establishment of the relation between them is done, it is necessary to record the information collected in a formalized manner. A format must be developed . The physical appearance of the format depends upon the system intended and the equipments available. For example, it may be manually operated SH list or a set of categories with variable length usable for computer input. Usually the SH list whether manual or computer based should be systematic and an alphabetical display.
In deciding on the entry of descriptors , the selected terms should be grouped systematically. For example : according to facets. The concepts denoted by the descriptors should be checked for their concept relations with other descriptors. Subject specialists and potential users should be consulted in selecting the descriptors and determine the concept relationships.
6.4 Systematic Arrangement of Subjects
The arrangement of main subjects must be directed to find a helpful order.
6.4.1 Universe of Subjects : Arrangement of Main Subjects
Each chunk of the universe of subjects into which the resulting homogeneous group of subjects may be deemed to fall is the 'main subject'. In a scheme for classification , main subjects are expected to be mutually exclusive and totally exhaustive of the universe of Subjects (US).
Since Colon Classification (CC) has been selected as the basis for constructing the present module in Kannada, the concepts of main subjects are discussed with complete reference to CC. The CC divides the US into three broad group of subjects namely, Natural Science, Humanities and Social Sciences. Subjects falling into each of these broad divisions are grouped into smaller sets of more or less homogeneous subjects. These form the traditional main subjects. For example, in the Natural Science, 'Applied Discipline' follows the 'Pure Discipline' on which the former is predominantly based.
D - Engineering follows C - Physics.
F - Technology follows E - Chemistry.
6.4.1.1 Principle of Increasing Concreteness
In the Natural Sciences, the main subjects denoting pure disciplines are arranged among themselves in the sequence of increasing concreteness from B Mathematics to Spiritual Experience and Mysticism.
6.4.1.2 Principle of Increasing Artificiality
In the Humanities and Social Sciences taken together, Pure disciplines are arranged among themselves in the sequence of increasing artificiality from 'Spiritual Experience and Mysticism' to Z 'Law'.
6.4.1.3 Partial Comprehension
A partial comprehension is interpolated in the schedule of Main Subjects in the appropriate position - that is, immediately preceding the first Main Subject it comprehends.
SZ - Social Sciences comprehends ' T - Education', 'U - Geography', 'V - History' , 'W - Political science', 'X - Economics', 'Y - Sociology' and 'Z - Law' and hence placed earlier to 'T - Education'.
6.4.1.4 Fused Main Subjects
Fused Main subjects emerges as a result of the interaction between subjects going with two or more subjects.
Example : Biochemistry
Astrophysics
The position of the new main subjects should be determined in such a way that it will help to preserve the helpful sequence among the Main Subjects.
Based on the above said principles, Appendix - 2 presents the list of Main Subjects in Kannada. As per the traditional Main Subjects, it may be rendered as:
viñaana maanava saastra samaaja viñaana
Science is viñaana in Kannada. But in some cases, saastra is also used depending upon the suitability and currency of the terms. The disciplines in its prime or developing stage was saastra. Ultimately when the disciplines gradually developed it became viñaana. For example: The present 'Linguistics' bhaasa viñaana was earlier 'Philology' bhaasa saastra. Like wise manassaastra became manooviñaana bhauta saastra became bhauta viñaana. Few have still retained saastra for example, jyotisya saastra.
6.4.2 Arrangement within Facets
By arranging the related subjects together, a helpful order could be found. For arrangement within the facets the general principles followed in pre-coordinate index are explained below.
6.4.2.1 Chronological
Arrangements in periods may be envisaged in subjects like 'Literature' and also applicable where generations may be considered sequentially.
6.4.2.2 Evolutionary
Very similar to chronological. For 'Biological Sciences' it suggests itself.
6.4.2.3 Increasing Complexity
In many subjects we find a steady development from basic ideas to their more complex applications.
Example : Mathematics
Arithmetics
Algebra
Geometry
6.4.2.4 Size
Many subjects lend themselves to a quasi arithmetical arrangement.
Example: Music - Solo
Duet
Trios, etc.
6.4.2.5 Preferred category
Most wanted items are at the beginning rather than in the middle or at the end. Preferred Category says that it may be removed from its normal place in the sequence and brought to the beginning.
Example : In Linguistics the preferred category may be 'Mother tongue'
6.4.2.6. Citation Order
The facets are cited in a citation order,such as in 'Literature',the language is first cited and then the literary form, period, etc. Mentioned below are some of the general principles which will help in establishing citation order:
- Subject before bibliographic form
- Purpose/Product - The primary facet will be the end product
- Dependence - Few operations are dependent on some material.
- Whole - Part - Machine facet should precede parts,that are subsidiary.
- Decreasing Concreteness - More concrete ones are always cited before less concrete ones. Best example is PMEST order in CC.
- Filing order - Filing order comes to picture in the study of the way in which a schedule must be written which will show clearly whereabouts in the sequence any given subject,simple or composite will be found.
- Principle of Inversion - This is reverse of citation order. Preserving the idea of general before special for both semantic and syntactic relationships is known as principle of inversion.
To construct classification schedules, the important points to be considered are, order of importance of the facets of the subject, the citation order and using the principle of inversion. It has to be decided whether the schedule will be enumerative or analytico synthetic. Keeping the advantages and brevity of the schedule, analityco synthetic method is adopted for the present study. Some of the advantages of analytico synthetic method are:
- Can list only simple subjects and not composite subjects.
- Include the foci within various facets.
- Citation order indicates how to combine these facets beginning with the least important and end with the most important.
- Just because single concepts are listed with none of their possible combinations, the schedule can be very brief and easy to handle.
- Principle of permutation - In chain indexing we come across forward chaining and backward chaining. There are chances in between these two, the middle order is called Permutation.
- Cognitive Approach - The citation order is relevant in subject definition.
Subject access from the point of view of information seekers, facets have to be derived with association of ideas at the thinking level. It is here, the cognitive models of knowledge organization are employed to articulate fundamental theory of library and information science. Cognitive paradigms effect a shift from system needs to user needs. Cognition is mental structure. It is referred to as conceptual model or mental model. This is one of the most significant concept to have come into information science during the past decade.
The basic idea of the cognitive approach is representation. Mental models mediate all social and situational aspects of information seeking through the form of representations. Mental models are nothing but representation of concepts . Concepts belong to our personal thinking, which can be communicated by pointing to objects, showing pictures, demonstrating a typical behavior etc., and by using words, technical terms and definitions.
This has been further discussed in this Chapter in section 6. It has also been tested whether it could be applied to Kannada.
6.5 Models of Indexing Systems
Mentioned below are some of the models of indexing systems.
6.5.1 Authority Lists Based Subject Indexing
This is a century old method primarily attributed to Charles Ammi Cutter. The rule is that, the specific subject of a document should be placed under a single heading which has the property of comprehensive and yet specificity. Secondly, every subject heading should have a designated item and should denote specific subject content of the item. Among the terms of synonyms, the preferred heading should be the one familiar with the searchers. ' See ' reference should be used for others. 'See also'' cross reference should lead the searcher from broader term to narrower terms and link related concepts at the same level of specificity location. These are some of the rules which are still valid in many subject heading formulations both in manual and computer based ones. Library of Congress Subject Headings ( LCSH ) and Sears List of Subject Headings are internationally accepted list of subject headings. Both use controlled vocabulary.
6.5.2 Subject - Chain (hierarchy) Based Indexing
Most of the precoordinate indexing systems are based on this chain procedure principle. Facet analysis of SRR,based on this principle, determines the correct rendering of the specific subject headings and the reference headings. He said that " the rules of chain procedure can be so framed as to implement any kind of decision about sought first heading and the other successive headings in conformity with the principle local variation." The development in this procedure is the Postulate Based permuted Subject Index or, in short POPSI. The chain of POPSI is made from facet analysis. Ganesh Bhattacharya has postulated a generalized subject indexing language with a set of elementary categories such as D - Discipline , E - Entity , A - Action , P - Property, M - Modifier. Every entry is a complete statement of the specific subject.
6.5.2.1 PRECIS
The first type of subject indexing using computer for the pre coordinate indexing , with a theory of chain procedure is PRECIS - Preserved Context Index System. This index system generates cross reference as well as subject thesaurus for different fields and has grammatically closest indexing technique for English and many other languages. It allows the user to locate the document at any significant term and establish at that point the context in which his chosen term has been considered by the author.
PRECIS has two levels of operations: Human level, wherein a subject statement is analyzed into a set of roles; Computer level, wherein the analyzed subject statement is programmed to be manipulated into producing variety of PRECIS subject index entries by computer processing and print-out.
FORMAT
1. PRECIS entry allows two line three position format.
| LEAD | QUALIFIER |
| DISPLAY |
This is called Lead - Qualifier Display format or standard format. The term in the Lead functions as the user's point of access to the index, the Qualifier establishes the wider context in which the lead is considered and the entries in the Display are context dependent on the lead. The method of rotation is employed to generate the different entries. The method of rotation is called 'shunting' . Entries in this standard format is generated by the shunting procedure. Terms in the input string are initially organized according to the principle of context dependency to generate sensible index entries.
The grammar of PRECIS is represented by the role operators and codes listed below. It is governed by two principles for organization, context depending and one to one relationship. This enables PRECIS to analyze the subject matter of a document. Role operators regulate the writing of conceptual terms (input strings). The main functions of the role operators are:
- To ensure within reasonable limit that subjects should be analyzed into elemental units according to common frames of references. This is done by rules of difference.
- To ensure that the concepts are written down consistently in the same order in input strings a filing order is built into it.
The Role Operators
The main line operators are as follows: Environment of observed system: 0 Location Observed 1 Object of Transitive action (key system) (core operators) System 2 Action / Effect 3 Agent of transitive action aspects. Data relating to observer 4 View point, as form 5 Sample population / study region 6 Target / Form Interposed operators Dependent (p) part / property Elements (q) Member of quasi generic group (r) Aggregate Concept inter link (s) Role definer (t) Author attributed association Coordinate concepts (g) Coordinate concept Differentiating (h) Non - lead direct difference Operators (i) Lead direct difference (j) Salient difference (k) Non lead indirect difference (m) Lead indirect difference (n) Non-lead parenthetical difference (o) Lead parenthetical difference (p) Date as difference V Downward reading component Theme inter links X First element is coordinate Y Subsequent element Z Element of common theme.2. The second format is the inverted format with the operators 4,5 and 6. These operators are associated with their own typography and also generate a special layout when one of these terms appear in the lead, this appears in bold and the dependent element in italics. In a PRECIS input string, the parts of the term are set down in the reverse of natural language order. For example, noun precedes the adjective. Each part is prefixed by a code to indicate whether or not that part is needed in the lead. The differencing operations are used to introduce the parts of a compound term (adjective).
3. The third format is predicate transformation. In PRECIS , concepts are organized strictly according to their logical roles (as agent, logical object etc) not their grammatical roles (as subject, predicate etc). The predicate transformation ensures that these various predicates are brought together and offered to user as a single alphabetical sequence, whether the term in the lead functions logically as an object or a performer. As the action and the key system together form the predicate, it is named as predicate transformation.
Under the passive form used by PRECIS, the syntactic complexity of a sentence can be reduced and made often suitable for making a string of terms.Programs for PRECIS are written in Assembler language . They are intended for DOS operations but can easily be converted to OS.
Grammatical basis of PRECIS was derived from a study of English sentence structure. For other languages, standard formula can be used to produce acceptable index entries in more than one natural language. To test this hypothesis , a number of small scale experiments have been carried such as , English strings were translated, concept by concept into their foreign language equivalents and the machine produced entries were judged for meaning. The results were encouraging in languages like French, German, Czech and other European languages. It has been tested on a range of Asian languages such as Persian, Tamil Hindi, Sinhala and in Chinese. Chinese lacks prepositions and different from other languages, but the system appears to work. Structure of PRECIS produce acceptable entries in various languages and research are still carried out in order to overcome certain problems. Further research may be takenup to develop an indexing system based on PRECIS in Kannada since it is compatible with Tamil which is one of the major Dravidian languages.
6.5.3. Unit - term (Post - coordinate Indexing)
The third and important model of indexing system is the post coordinate indexing. In this we come across:
- Post controlled vocabulary
- Coordinate indexing
- Key word indexing
In the present state of art, thesaurus is gaining popularity in almost all the disciplines. The searcher in a natural language system needs a thesaurus of some type. This gives rise to the concept of post - controlled vocabulary, which is the system in which no control is imposed at the time of input but the vocabulary is controlled at the output stage, having the characteristics of components of a controlled vocabulary for exploitation by the user. In the coordinate index,each index term or uniterm is independent of all other terms in the system as a unique autonomous access point to all relevant items in the collection. While conducting the search, two or more terms may be coordinated to form a composite search statement.
Key word indexes are automatic indexes. There are two ways: (a) word is extracted from the text, the title or the abstract and (b) concept indexing. For word indexing, computer - generated index is the permuted-title index KWIC is an example. It is a key word in context index. Later versions are key - word and context index (KWAC) and keyword out of context(KWOC). Titles of the documents are put in a computer readable form. Then it chooses the significant words , prints each title in such a way that each significant word appears in a designated key position and all titles are arranged alphabetically by the significant word and the letters following it. Their usefulness depends on the use of factual, unambiguous, significant word in titles, abstract and text. KWIC and KWOC in Kannada are presented in Appendix - 8 and 9 .Though this type of indexing is very near to natural language, the complex style and vocabulary full of connotations, the computer - extracted indexes give a way to human indexers. It is here that semi-automatic indexes such as chain index - PRECIS, POPSI etc., would work.
6.6 Recent Developments in Indexing
The developing field of contemporary interest in indexing language is 'Cognitive Science. The word 'cognition' comes from the Latin which means 'to know' . Cognitive science is an interdisciplinary field drawing inputs from the fields of Psychology, Behavioral studies, Computer Science, Engineering, and Information Science. In designing information retrieval system, the most relevant study is that, how mind process information. Research is still on the lookout in integrating the bibliographic knowledge representation into high powered retrieval systems incorporating variety of knowledge representations such as 'hyper text , 'cluster analysis' and representations incorporating reasoning. Hypertext was coined by Ted Nelson in 1960s to refer to an electronic document consisting of a network of nodes , which are text fragments of some sort and links, which are relationships connecting the nodes. Cluster analysis was also started in 1960s as automatic classification wherein computers were used to classify documents by purely automatic means. The classes were derived using multi variate techniques such as, co - occurrence of words. These fall much short of human ingenuity. Hence an ideal automatic system should be modeled on cognitive paradigms.
In late 1960s, the term 'knowledge representation' was coined in the context of artificial intelligence. Artificial intelligence is attempting to create machines that can simulate man's mental power and with the result it has prompted researchers in information science to develop computational models. A system has to be developed in such a way that, it can understand syntax and semantics of natural language and do the content analysis of a document. The developments in linguistics, in particular, the contribution of Noam Chomsky in formal grammars have helped the developments in natural language processing (NLP). Introducing knowledge into information retrieval system is knowledge representation. Production rules, predicate logic, semantic nets and frames are examples of knowledge representation. All these are linked to each other.
6.6.1 Frame Based Knowledge Representation
The frame concept was invented by Marvin Minsky (1975). A frame is a data structure for representing a stereotyped situation. If the top level of a frame is fixed and represents things about the supposed situation, the lower levels have many terminal slots that must be filled by specific data which represent facts. Otherwise frames will not be recognized. Collections of related frames are linked and constitutes frame system. Frames are abstractions on groups of facts and they organize facts. Frames are useful for understanding of NL by computers. For example verbs and nouns can be frames and modifiers can be slots. Frame based knowledge representation models are of three types. They are:
- Rule based : Which says any knowledge can be reduced to some kind of rule.
- Semantic nets : The concepts in the world are semantically related to each other.The semantic models are hierarchically structured.
- Frame based : They are the extension of semantic net, but feature based. If there are attributes, frames can be developed under nodes.
In the frame based knowledge representation model , each NP is treated as an object. The properties and its relation to other objects has to be expressed to each object NP.
Object representation aggregates several related predicate logic formulas into large structures called units or frames that are identified with characteristic objects of the domain of discourse. The appropriate unit is accessed when information is required in one of these objects. All the relevant facts are retrieved about the objects. To incorporate all the information on the object, a structure is created. Each pair of attributes and value in the frame is called a slot, where attribute is the 'slot name' and value is the 'slot value' and the frame is 'slot and filler' notation. Object oriented representation is an alternative formalism for predicate logic representation (Nilson1980).
In the information retrieval situation, the title of the document has to be transformed into expressive title , which constitutes the content of the document in the form of key words. In the object oriented approach, key terms are considered as objects. These object NPs have to be identified indicating their properties and their relation to other objects. In subject classification NP plays a very important role since the expressive titles do not contain verbs. Instead, the noun variants of a verb appears in most of the document titles.In IL, verbs in its noun form or variant are expressed as 'Energy' facet in S R Rs analytico synthetic school of thought and 'Action' in few other ILs. For the purpose of IL, it is sufficient to build a NL parser in order to identify NPs. So, when a parser has to be developed, important thing is to decide first, what purpose it is going to serve and the objective of the study. The definition of PARSER may also change depending upon the purpose.
For example: Linguists may write the grammar as S = NP + VP.
In index language situation, this will be written as: S = NP - V - NP or NP NP
That is, verb is not at all taken into consideration. Any one can observe that a document title will never be a complete sentence to adopt the parsers developed by linguists for NLP. It will be sometimes a word, a phrase or metaphor.
If we take the following sentence, for example, 'She sings Karnatic music well,' the NLP parser will definitely agree the above sentence. Here the verb 'sing' will have the attributes such as : Sing - transitive verb,plural, animate, singular precedence ,etc. In order to have subject verb agreement. When we take the following title into consideration, 'A guide to Karnatic music singers,' though the verb 'sing' is used in rendering the title, the morpheme 'sing' has got some addition or morphological inflection '-er' to make it a NP. Keeping all these factors in view, it is sufficient if the PARSER can recognize the NPs instead of NPs and VPs for the purpose of IL.
Though the term 'cognition' is getting popular in the present information era, this was covertly realized in 1930s by S R R, which he called 'Absolute syntax'. The definition he gave for it was, "The sequence in which the component ideas of compound subjects going with a basic subject arrange themselves in the minds of the majority of normal intellectuals." In a group of learned people, all think in the similar way in structuring the knowledge. For the semantic model in NLP frames, his contribution PMEST is the semantic order.His index language 'Colon Classification' was an indigenous product. Although his theories, postulates and principles are internationally recognized, the syntax has not been accepted at the computational level. Hence information scientists had to depend upon the in built phrase structure grammar in the PROLOG language for developing PARSERs. This problem made information scientists to master specific grammars adopted in NLP.
6.7 Conclusion
To govern the generation and rendering of SH , ISO standard on thesaurus construction (ISO 2788) may be followed. While formulating the rules for Kannada spelling system, 'Kannada sailikaipidi' can be the model. IL prepared following the principles discussed in this chapter needs to be continuously updated. Keeping the advantages and brevity of the schedule analytico synthetic method is advisable. PRECIS discussed in this chapter depicts how useful the subject - chain (hierarchy) based indexing which is quite ideal to prepare the pre - coordinate IL system. For retrieval purpose unit term or post - coordinate systems are useful. For the purpose of IL in the NLP environment it is enough to develop parsers that would identify the NPs instead of NPs and VPs.
The next chapter discusses application of TG for analyzing the document titles in Kannada.
*** *** ***
CHAPTER SEVEN
TRANSFORMATIONAL GRAMMAR AND ANALYSIS OF
DOCUMENT TITLES IN KANNADA
| 7.0 | Introduction |
| 7.1 | Purpose |
| 7.2 | Specificity |
| 7.3 | Sample Data |
| 7.4 | Lengthwise Complexity of Words Used in Rendering titles |
| 7.5 | Classification |
| 7.5.1 | Analysis of Titles Derived by Experts |
| 7.5.2 | Analysis of Published Titles |
| 7.6 | TG Rules to Kannada Expert System |
| 7.6.1 | Application of TG |
| 7.6.1.1 | Step I - Identification of Syntactic Categories |
| 7.6.1.2 | Step II - Generation of Syntactic Structure |
| 7.6.1.3 | Step III - Semantic Interpretation of Titles |
| 7.6.1.4 | Step IV - Identification of Elementary Categories |
| 7.6.1.5 | Step V - Generation of Subject Entries |
| 7.7 | Classificatory Structure Based on CC |
| 7.8 | Conclusion |
7.0 Introduction
The two dimentions of indexing language are (a) Classificatory language and (b) natural language approach. Natural language approach facilitates the information retrieval in natural language which is very near to the user community. This present chapter tackles the natural language approach with the help of infolinguistic application. As stated earlier (1.1.1) the representational property of a language is the syntax.. In syntax, the grammar adopted for this study is the Transformational Grammar(TG) from the Chomskian school of thought.
The theoretical part of TG has been discussed in detail in Chapter Two. The present chapter discusses application of it to the analysis of document titles in Kannada.
TG deals with two types of relationships.
- Hierarchical (What dominates what?)
- Positional (What comes after what?)
They are called dominance and positional relationships. In a sentence, subject is dominated as it directly comes from the sentence `S'. The verb and object Noun Phrase(NP) is dominated by the Verb Phrase(VP). Subject NP is in higher position and object NP is in lower position dominated by VP.
As said in the previous Chapter Six, (6.6.1) titles are not complete sentences and the transformational rules derived for the analysis of sentences in the natural language cannot be applied to them without modification. Because, usually the document titles do not contain verbs. Instead, the noun varients of a verb appear. Document titles are Noun phrases derived from sentences. Their dominance and positional relationships could be demonstrated in the form of a tree diagram as follows: (Not presented here for technical reasons. Editor, Language in India.)
Example: mahile mattu shikshana `Women and education.' `mahile' and `shikshana' are two equivalent NPs dominated by a major NP. This major NP is derived from a sentence of the type:
avaru mahileyarige shikshana koduttaare
`they women(dat.case) education give-pl'
`They give education to women'.
The process of derivation from the above sentence can be illustrated from the following tree-diagram. (Not presented here for technical reasons. Editor, Language in India.)
In this tree-diagram, the application of nominalisation transformation is done. With the consequence four process, namely, 1. Verb deletion, 2.Dative case deletion, 3.Subject Noun deletion, and 4.Replacement by genitive case or genetivization takes place . With the result, `Mahileyara shikshana' is obtained. From this NP (Genetive phrase), by means of conjunction addition,coordination and deletion of genitive case and plural marker, the NP `mahile mattu shikshana' ( women and education ) is derived.
While applying the TG rule each and every concept has been tested. The deep structure helps in analyzing the semantic elements involved in rendering the title. Since the titles have to be precise and they exhibit the important concepts involved in the document, deep structure helps in the semantic interpretation. Further analysis could be done tagging each concepts present in the title.
7.1 Purpose
As discussed in derived indexing 6.5.3, by the application of computers with relevent software designed for information management and retrieval, Key Word In Context, Key Word Out of Context, etc., could be achieved in Kannada. But they are more in a mechanical manner and considers each word as the word in context. In spite of its advantages, the belief of these systems is that the content of the document is represented in its title. The following questions arise.
- When in the index, the keyword is in context?
- How much context is required ?
- Will the document title really reflect the content of the ocument?
In order to solve the above said problems and overcome the same, systems such as PRECIS , POPSI etc., came in to existence having the idea of content analysis using both manual and automated methods. Both PRESIC and POPSI represent efforts towards universality in structuring IL. Since the indexing was permuted none of the terms were left unindexed from the title and also though the title did not represent the content of the document, these systems tried to incorporate those content keywords in their indexing system. PRECIS while considering the content of a document did not have a theory as to how it should be represented. POPSI , overcame that problem, because it is based on SRR's analytico synthetic method and has provided pure theoretical background for content analysis.
Further improvement over POPSI is the Natural Language Processing(NLP), facilitating the information retrieval in NL. As discussed in 6.6.1, depending upon the need, the NLP rules could be formulated and modified. This Chapter discusses the extent to which TG can be applied to develop parsers in analyzing document titles in Kannada.
7.2 Specificity
While designing a classification scheme, the collection and the user have to be involved at different stages. Because the IRS should match with the users perception. Keywords are used as a search media in an IRS . Combination of keywords leads to phrase formation and with the result titles are formulated . In an IRS user interaction, search formulation can be formulated as a structured presentation. This could be referred to the attributes of an IL, such as scheme of classification, thesaurus etc.
The other way is to tackle the users query with NL itself. Formulating syntactic structure in NLP, and developing parsers are the main function in this operation.
7.3 Sample Data
To take on the above said problems, an experiment was performed (a) first is from users side and (b) next from collection side. The discipline selected for the study was `shikshana' (Education).
(a) User's side
1. Ten experts in the discipline `Education' were selected.
2. Keywords were listed alphabetically from fifty published titles in `Education'.(Appendix:4) and administered among the ten educationists. Using this list they were asked to derive ten titles each in `Education' without referring to already published titles. They were asked to list out the approachable keywords by the users from the titles they have derived for the purpose of information retrieval.
Since few words were root words, the experts were allowed to use morphological inflections and proper nouns such as, names of person, place,etc., depending upon the context. For demonstration of brain storming among experts(6.3), selection of ten experts in the field was felt one of the methods. They included faculty in the post-graduate department of education, University of Mysore, both regular and correspondence course and experts from District Primary Education Programme, Karnataka.
(b)Collection Side:
The samples here consisted of fifty already published titles in `Education'. The key words administered among experts were listed from these fifty titles only.
7.4 Length Wise Complexity of Words Used in Rendering Titles
(Not presented here for technical reasons. Editor, Language in India)
Derived and Published titles, Table 5 No.of.words No.of titles Total no.of No of titles X Derived - Y words - X*Y Published - Z X*Z % 1 0 0 0 0 0 2 8 16 13 26 26 3 29 87 22 66 44 4 28 112 9 36 18 5 19 95 5 25 10 6 9 54 - - - 7 2 14 - - - 8 4 32 - - - 9 1 9 - - - Total 100 419 50 173
This table illustrates the total number of terms the experts have used in title creation (Y), which has minimum two to maximum nine words. In total 419 words are used to form 100 titles. The same with the 50 published titles (Z) has two to five words and in total 173 words are used to form 50 titles. In both the cases titles using three words are maximum and single word titles are nil.
7.5 Classification
The words were tagged with the parts of speech in order to:
- Find grammatical relation between concepts.
- Find syntactic process based on the methodology mentioned in 7.0 of this chapter while discussing TG rules.
- Find classificatory structure based on CC fundamental categories(FC).
- Based on the above,
- Forming rules for the analysis of document titles in Kannada.
- Forming rules in Natural language processing (NLP) environment in Kannada.
7.5.1 Analysis of Titles Derived by Experts
The combination of both structural types and classificatory structure for 100 titles derived by the experts is as follows: The abbreviations used here are listed in abbreviations list under the sub heading Chapter7. Also, though an adverb modifies a verb, since in document titles, the verb is covertly expressed or verb will be an understood element and hence, adverb appears. The participles are derived from verbs and they qualify the noun. Attribute is a noun which becomes an adjctive and becomes attribute. Though it has got the function of an adjective, in the parts of speech, it is not adjective but an attribute.
a.Title
b.Grammatical Relation
c.Syntactic Process/Phrasal category
d.Classicicatory Structure
Expert 1
1. a. tatva darshana mattu shiksana
b. NP + Conjunction + NP
c. Coordinate Phrase
d. BS + E + IS(a) + BS
2. a. shikshanadalli sankhyaasaastra
b. [NP + Loc] + NP
c. Locative Phrase
d. BS + IS(b) + BS
3. a. praathamika shikshanada gunamatta
heccisuvalli kalikeya
kanistha mattagala paatra
b. Atr + [NP + Gen] + NP + [Participle NP + Loc] + [NP +
Gen] + Adj + [NP + Pl + Gen] + NP
c. Attributive, Genitive and Locative Phrase
d. P + BS + M + E + E + M + P
4. a. shikshanadalli samsoodhanaa vidaanagalu
b. [NP + Loc] + NP + [NP + Pl]
c. Locative Phrase
d. BS + P
5. a. pracalita shikshana vyavastheyalliv
khaasagi samsthegala paatra
b. Atr + NP + [NP + Loc] + Adj + [NP + Pl + Gen] + NP
c. Attributive,Locative and Genitive Phrase
d. T + BS + P + P + P + E
6. a. nirnaayaka aadhaarita maulyamaapana
b. Atr + Atr + NP
c. Attributive Phrase
d. M + IF(sk) + E
7. a. maulyamaapana siddhaanta mattu
aacarane
b. NP + NP + Conj + NP
c. Coordinate Phrase
d. E + P + IF(j) + E
8. a. nyuunateyulla makkaligaagi shikshana
b. Rel.Part + Vbl.Part + NP
c. Participial Construction
d. P + P + BS
9. a. indina prashikshana vyavastheyalli sudhaaranegalu
b. Atr + NP + [NP + Loc] + [NP + Pl]
c. Attributive and Locative Phrase
d. T + BS + E
10. a. unnata shikshanadalli
sudhaaranegalu
b. Atr + [NP + Loc] + [NP + Pl]
c. Attributive and Locative Phrase
d. P + BS + E
Expert 2
1. a. shikshakara shikshanadalli
gunaatmaka badalaavanegalu
b. [NP + Gen] + [NP + Loc] + Atr + [NP + PL]
c. Gen, Loc and Attributive Phrase
d. D + BS + M + E
2. a. vyaasangada abhyaasagalu
mattu preerane
b. [NP + Gen] + [NP + Pl] + Conj + NP
c. Gen and Coordinate Phrase
d. P + E + IA(t) + E
3. a. shikshakarige tatvashaastrada
avashyakate mattu
shikshanadalli adara sthaana
b. [NP + Dat] + [NP + Gen] + NP + Conj + [NP + Loc] + [NP + Gen] + NP
c. Dat, Gen, Loc and Coordinate Phrase
d. P + BS + IS(a) + BS
4. a. unnata shikshanada samasyegalu
b. Adj + [NP + Gen] + [NP + Pl]
c. Genitive Phrase
d. P + BS + M
5. a. shikshana kramadalli
taayinudigee agrasthaana eeke?
b. NP + [NP + Loc] + [NP + Dat] + NP + Inter. form
c. Loc, Dat and Interrogative Phrase
d. BS + P + M
6. a. abhyaasa boodhaneyalli suukshma
boodhaneya mahatva
b. Atr + [NP + Loc] + Atr + [NP + Gen] + NP
c. Attr, Loc and Genitive Phrase
d. P + E + M
7. a. mahilaa saaksharateya
pragatige saamuuhika prayatna
b. NP + [NP + Gen] + [NP + Dat] + Atr + NP
c. Gen, Dat and Attributive Phrase
d. P + P + E + E
8. a. praudhashaalaa shikshanadalli
ittiicina belavanigegalu
b. Atr + NP + [NP + Loc] + Adj + [NP + Pl]
c. Attributive and Locative Phrase
d. P + BS + T + E
9. a. shikshana ksheetrakke odagisiruva
aarthika sampanmuulagala maulyamaapana
b. NP + [NP + Dat] + Rel.Part + Adj + [NP + Pl + Gen] + NP
c. Dat, Gen and Participial Construction
d. BS + E + M + E
10. a. kannadadalli shaikshanika saahitya
b. [NP + Loc] + Atr + NP
c. Locative and Attributive Phrase
d. P + BS + P
Expert 3
1. a. vaiyaktika samasyegala
manoovaignaanika muulaadharagalu
b. Atr + [NP + Pl + Gen] + NP + [NP + Pl]
c. Atttributive and Genitive Phrase
d. P + M + BS + P
2. a. praudha shikshanadalli
sudhaaranegala agatya
b. Adj + [NP + Loc] + [NP + Pl + Gen] + NP
c. Locative and Genetive Phrase
d. P + BS + E + M
3. a. saamaajika badalaavaneyalli
mahileya paatra
b. Atr + [NP + Loc] + [NP + Gen] + NP
c. Atr, Loc and Genitive Phrase
d. BS + E + P + M
4. a. karnaatakadalli vishvavidyaalayagala
itihaasa
b. [NP + Loc] + [NP + Pl + Gen] + NP
c. Locative and Genitive Phrase
d. S + P + P
5. a. boodhanaa kshetradalli
kraantikaari belavanige
b. [NP + Loc] + Atr + NP
c. Locative and Attributive Phrase
d. BS + M + E
6. a. shikshaka, pariikshaapaddati
mattu kaanuunu
b. NP + NP + Conj + NP
c. Coordinate Phrase
d. BS + P + E + M
7. a. bhaashaa kalike mattu
samskruti
b. Atr + NP + Conj + NP
c. Attributive and Coordinate Phrase
d. P + E + IS(a) + BS
8. a. niraksharate nivaaraneyalli
nuutana aacaranegalu
b. NP + [NP + Loc] + Adj + [NP + Pl]
c. Locative Phrase
d. BS + E + M + E
9. a. krushi vidyaabyaasada
prcalita tatvagalu
b. Atr + [NP + Gen] + Adj + [NP + Pl]
c. Attributive and Genitive Phrase
d. BS + BS + T + P
10. a. shikshakanige saahitya mattu
samskrutigala vyaasangada
avasyakate
b. [NP + Dat] + NP + Conj + [NP + Pl] + [NP + Gen] + NP
c. Dat, Gen and Coordinate Phrase
d. BS + P + BS + IS(a) + BS + E + M
Expert 4
1. a. praathamika shikshana ksheetradalli
raastravu saadhiruva pragati
b. Adj + NP + [NP + Loc] + NP + Rel.Par + NP
c. Locative and Relative Participial Construction
d. P + BS + S + E + P
2. a. bhaaratadallina pracalita
haikshanika samasyegalu b. [NP + Loc + Gen] + Adj + NP + [NP + Pl]
c. Locative and Genitive Phrase
d. S + T + BS + M
3. a. shikshanadalli manoovignaana,
maulyamaapana mattu sankhyaashaastra
b. [NP + Loc] + NP + NP + Conj + NP
c. Locative and Coordinate Phrase
d. BS + BS + E + IS(a) + BS
4. a. aadhunika boodhane -
ondu kale athavaa vignaana?
b. Atr + NP + NP + Neg.Conj + NP + Inter. intonation
c. Coordinate and Interrogative Phrase
d. T + BS + BS + IS(a) + BS
5. a. indina shaikshanika aadalita
mattu pariikshaa paddhatiyalli sudhaaraneya avashyakate
b. Attr + NP + NP + Conj + Adj + [NP+Loc] + [NP+Gen] + NP
c. Attr,Coor,Loc and Genitive Phrase
d. T + BS + P + IF + P + E + M
6. a. praathamika hantadalli
kannada bhaashaa boodhane
b. Adj + [NP+Loc] + NP + Atr + NP
c. Locative and Attributive Phrase
d. P + P + E
7. a. shikshana ksheetradalli mahileyara paatra:
nuutana raastriiya shikshana niiti
b. NP + [NP + Loc] + [NP + Pl + Gen] + NP :
NP + [NP +Gen] + Atr + NP
c. Loc,Gen and Attributive Phrase
d. BS + P + T + S + P + M
8. a. krushi mattu kaanuunu
kshetragalalli vignaana vyaasangada agatya
b. NP + Conj + NP + [NP + Pl + Loc] + NP + [NP + Gen] + NP
c. Coor,Loc and Genitive Phrase
d. BS + IS(a) + BS + BS + BS + M
9. a. vidyaarthigala daihika mattu naitika
belavanige: shaalaa pathyakramadalli ivugala paatra
b. [NP +Pl + Gen] + Atr + Conj + Atr + [NP + Dat]:
Atr + [NP + Loc + [Pron +Pl] + NP
c. Gen,Atr,Coor,Dat and Locative Phrase
d. P + P + IF + P + E + P + P + M
10. a. proudhashaalaa hantadalli vruttipara kalike
b. Atr + NP + [NP + Loc] + NP + NP
c. Atributive and Locative Phrase
d. P + P + E
Expert 5
1. a. indina shaikshanika agatya
b. Atr + NP + NP
c. Attributive Phrase
d. T + BS + M
2. a. saarvatrika shikshana: indina agatya
b. Atr + NP : Atr + NP
c. Attributive Phrase
d. P + BS + T + M
3. a. daihika shikshanadalli yooga
b. Atr + [NP + Loc] + NP
c. Attributive and Locative Phrase
d. P + BS + P
4. a. maguvina maanasika belavanige: shikshakana paatra
b. [NP + Gen] + Atr + NP : [NP + Gen] + NP
c. Genitive and Attributive Phrase
d. P + P + E + P + M
5. a. boodhaneyalli aakarshane
b. [NP + Loc] + NP
c. Locative Phrase
d. BS + E
6. a. maulyamaapanavillada shikshana apuurna
b. [NP +Neg.Part] + NP + NP
c. Negative Relative Participial
d. E + BS + M
7. a. shiksana mattu manoovignaana
b. NP + Conj + NP
c. Coordinate Phrase
d. BS + IS(a) + BS
8. a. karnaatakadalli kaaleeju shikshana
b. [NP + Loc] + Atr + NP
c. Locative and Attributive Phrase
d. S + P + BS
9. a. aadhunika pariikshaapaddhati
b. Atr + NP
c. Attributive Phrase
d. T + P + M
10. a. kannadadalli vignaana : shikshakara kaipidi
b. [NP + Loc] + NP : [NP + Pl + Gen] + NP
c. Locative and Genitive Phrase
d. P + BS + P + P
Expert 6
1. a. karnaatakada pracalita shikshana samasyegalu
b. [NP + Gen] + Atr + NP + [NP + Pl]
c. Genitive and Attributive Phrase
d. S + T + BS + M
2. a. indina shaalegalalliruva niyamagalu
mattu naitika paddhatigalu
b. Atr + [NP + Pl + Loc] + Rel.Part + [NP + Pl] + Conj + Atr + [NP + Pl]
c. Atr,Loc,Rel.Part and Coordinate Phrase
d. T + P + P + IF(j) + M + P
3. a. shikshanadalli kraantikaari badalaavane
b. [NP + Loc] + Atr + NP
c. Locative and Attributive Phrase
d. BS + M + P
4. a. shikshana samasyegalu : aadhunika nivaaranegalu
b. NP + [NP + Pl] + Atr + [NP + Pl]
c. Attributive Phrase
d. BS + M + T + E
5. a. aadhunika bhaaratadalli shikshaka,
boodhane, maulyamaapana
b. Atr + [NP + Loc] + NP + NP + NP
c. Locative Phrase
d. T + S + P + E + M
6. a. nuutana kalikaa vidhaanagalu mattu
pariikshaa paddhati
b. Atr + Atr + [NP+Pl] + Conj + NP
c. Attributive and Coordinate Phrase
d. T + E + M + IF(j) + P
7. a. taayinudiyalli bhaashaa kalike
b. [NP +Loc] + Atr + NP
c. Locative and Attributive Phrase
d. P + P + E
8. a. maulyamaapanada sudhaarane
b. [NP + Gen] + NP
c. Genitive Phrase
d. E + E
9. a. vruttishikshana,shaalaaksheetragalu
mattu adara agatya
b. Atr + NP + [NP + Pl] + Conj + [Pron + Gen] +NP
c. Attr,Gen and Coordinate Phrase
d. P + BS + P + P + IF(j) + M
10. a. raastrada aarthika belavanigeyalli
mahileya paatra
b. [NP + Gen] + Atr + [NP + Loc] + [NP + Gen] + NP
c. Gen,Attr and Locative Phrase
d. S + P + E + P
Expert 7
1. a. aadhunika bhaaratadalli naitika belavanige
b. Atr + [NP + Loc] + Adj + NP
c. Attributive and Locative Phrase
d. T + S + M + E
2. a. pariikshaapaddhatiyalli badalaavane
b. [NP + Loc] + NP
c. Locative Phrase
d. P + E
3. a. karnaatakadalli kannadakee agrasthaana
b. [NP + Loc] + [NP + Dat] + NP
c. Locative and Dative Phrase
d. S + P + M
4. a. niraksharate nivaaraneyalli mahileya sthaana
b. NP + [NP + Loc] + [NP + Gen] + NP
c. Locative and Genetive Phrase
d. P + E + P + M
5. a. shikshanavruttiyalli mahileya manoovignaana
b. [NP + Loc] + [NP + Gen] + NP
c. Locative and Genitive Phrase
d. BS + IS(b) + P + BS
6. a. aadhunika shikshana paddhatiyalli adhyaapakana paatra
b. Atr + [NP + Loc] + [NP + Gen] + NP
c. Attr,Loc and Genitive Phrase
d. T + BS + P + P
7. a. indina shaalegalalli sankhyaashaastrada boodhane
b. Atr + [NP + Loc] + [NP + Gen] + NP
c. Attr,Gen and Locative Phrase
d. T + P + IS(b) + BS + E
8. a. vidyaabhyaasadalli maulyamaapanada agatya
b. [NP + Loc] + [NP + Gen] + NP
c. Locative and Genitive Phrase
d. BS + E + M
9. a. kaaleejugalalli samskrutiya sudhaarane
b. [NP + Loc] + [NP + Gen] + NP
c. Locative and Genitive Phrase
d. P + IS(b) + BS + E
10. a. shikshana kshetradalli khaasagi samsthegala paatra
b. [NP + Loc] + Atr + [NP + Pl + Gen] + NP
c. Loc,Attr and Genitive Phrase
d. BS + P + M
Expert 8
1. a. mahilaa shikshana : indina agatya
b. Atr + NP : Atr + NP
c. Attributive Phrase
d. P + BS + T + M
2. a. unnata shikshanadalli kraantikaari badalaavane agatya
b. Atr + [NP + Loc] + Atr + NP + NP
c. Attributive and Locative Phrase
d. P + BS + E + M
3. a. vidyaabhyaasa sudhaaraneyalli khaasagi samsthegala aadyate
b. NP + [NP + Loc] + Atr + [NP + Gen] + NP
c. Loc, Attr and Genitive Phrase
d. P + E + P + M
4. a. karnaatakadalli kannadadallee shikshanada agatya
b. [NP + Loc] + [NP + Loc + Emphatic] + [NP + Gen] + NP
c. Loc,Emphatic and Genitive Phrase
d. S + P + BS + M
5. a. nuutana shaikshanika sudhaarane : indina avashyakate
b. Adj + NP + NP : Atr + NP
c. Attributive Phrase
d. T + BS + E + T + M
6. a. shikshanadalli janteya vaiyaktika paatra
b. [NP + Loc] + [NP + Gen] + Atr + NP
c. Loc,Gen and Attributive Phrase
d. BS + P + M
7. a. indina shikshanada pariikshaapaddhatiyalli badalaavaneya agatya
b. Atr + [NP + Gen] + [NP + Loc] + [NP + Gen] + NP
c. Attr, Gen and Locative Phrase
d. T + P + E + E + M
8. a. khaasagiisamsthegalige shikshana : nuutana suutra
b. Atr + [NP + Dat] + NP :Adj + NP
c. Attributive and Dative Phrase
d. P + BS + T + M
9. a. praathamika shikshana :indina samasyegalu
b. Atr + NP : Atr + [NP + Pl]
c. Attributive Phrase
d. P + BS + T + M
10. a. vrutti mattu shikshana : aarthika belavanigeya muulaadhaara
b. NP + Conj + NP : NP + [NP + Gen] + NP
c. Coordinate and Genitive Phrase
d. P + BS + E + M
Expert 9
1. a. vishvavidyaanilayagalalli kannada boodhaneya agatya
b. [NP + Pl + Loc] + Atr + [NP + Gen] + NP
c. Loc,Attr and Genitive Phrase
d. P + P + E + M
2. a. shikshanada khaasagiikarana
b. [NP+Gem]+NP
c. Genitive Phrase
d. BS + P + E
3. a. praathamika shikshanadalli bhaashe mattu manoovignaana
b. Atr + [NP + Loc] + NP +Conj+NP
c. Attr,Loc and Coordinate Phrase
d. P+BS+P+IS(g)+BS
4. a. nuutana shikshanapaddhati
b. Adj + NP
c. Adjectival Phrase
d. T + BS + P
5. a. maatrubhaashaa shikshana
b. Atr + NP
c. Attributive Phrase
d. P + BS
6. a. shikshanadalli saahitya vyaasanga
b. [NP + Loc] + Atr + NP
c. Locative and Attributive Phrase
d. BS + IS(b) + BS + E
7 a. shikshanada saamaanya samasyegalu
b. [NP + Gen] + Atr + [NP +Pl]
c. Genitive and Attributive Phrase
d. BS + M
8. a. raastradalli niraksharateya nivaarane
b. [NP + Loc] + [NP + Gen] + NP
c. Locative and Genetive Phrase
d. S + P + E
9. a. saamuuhika shikshana
b. Atr + NP
c. Attributive Phrase
d. P + BS
10. a. kraantikaari shikshanada maulyamaapana
b. Atr + [NP + Gen] + NP
c. Attributive and Genitive Phrase
d. P + BS + E
Expert 10
1. a. shikshana mattu raastrada aarthika belavanige
b. NP + Conj + [NP + Gen] + Atr + NP
c. Coordinate, Genitive and Attributive Phrase
d. BS + IS(a) + S + BS + E
2. a. shaikshanika aadalita sudhaarane
b. Atr + Atr + NP
c. Attributive Phrase
d. BS + P + E
3. a. shaikshanika manoovignaana
b. Atr + NP
c. Attributive Phrase
d. BS + IS(g) + BS
4. a. shaalaa vignaana maulyamaapana
b. Atr + Atr + NP
c. Attributive Phrase
d. P + BS + E
5. a. praathamika shaalegalalli kannada boodhane
b. Atr + [NP + Pl + Loc] + Atr + Np
c. Attributive and Locative Phrase
d. P + P + E
6. a. praathamika shikshanada samasyegalu
b. Atr + [NP + Gen] + [NP + Pl]
c. Attributive and Genitive Phrase
d. P + BS + P
7. a. pracalita maulyamaapana paddhatigalu
b. Atr + NP + [NP + Pl]
c. Attributive Phrase
d. T + E + M
8. a. bhaashaa belavanigege shikshanada koduge
b. Atr + [NP + Dat] + [NP + Gen] + NP
c. Attr,Dat and Genitive Phrase
d. P + E + BS + E
9. a. pariikshaa paddhati sudhaarane:indina avashyakate
b. NP + NP : Atr + NP
c. Attributive Phrase
d. P + E + T + M
10. a. shikshana mattu kaanuunu
b. NP + Conj + NP
c. Coordinate Phrase
d. BS + IS(a) + BS
7.5.2 Analysis of the Published Titles
The detailed analysis for each title is given below for the published titles.
1. a. aadhunika bhaaratiiya shikshana
b. Atr + [NP + Gen] + NP
c. Attributive and Genitive Phrase
d. T + S + BS
2. a. bhaaratiiya shikshanada itihaasa
b. [NP + Gen] + [NP + Gen] + NP
c. Genitive Phrase
d. S + BS + P
3. a. bhaashaa shikshana
b. Atr + NP
c. Attributive Phrase
d. P + BS
4. a. bhaaratadalli proudha shikshanada belavanige
b. [NP + Loc] + Atr + [NP + Gen] + NP
c. Locative and Genitive and Attributive Phrase
d. S + P + BS + E
5. a. boodhaneya tatva
b. [NP + Gen] + NP
c. Genitive Phrase
d. BS + P
6. a. boodhaneya saamaanya niyamagalu
b. [NP + Gen] + Atr + [NP + Pl]
c. Genitive and Attributive Phrase
d. BS + P
7. a. daihika shikshana
b. Atr + NP
c. Attributive Phrase
d. P + BS
8. a. indina shaikshanika samasyegalu
b. Atr + NP + [NP + Pl]
c. Attributive Phrase
d. T + BS + P
9. a. janateyalli vignaanada prasaara
b. [NP + Loc] + [NP + Gen] + NP
c. Locative and Genitive Phrase
d. P + BS + E
10. a. juniyar kaaleeju shikshana
b. Atr + NP + NP
c. Attributive Phrase
d. P + BS
11. a. kalisuva saamaanya paddhatigalu
b. Rel.Part + Atr + [NP + Pl]
c. Relative Participial and Attributive Phrase
d. E + P
12. a. kannada bhaashaa boodhane
b. Atr + NP + NP
c. Attributive Phrase
d. P + E
13. a. karnaataka shaikshanika itihaasa
b. NP+Atr+NP
c. Attributive Phrase
d. S + BS + P
14. a. mahile mattu shikshana
b. NP + Conj + NP
c. Coordinate Phrase
d. P + BS
15. a. naitika shikshana
b. Atr + NP
c. Attributive Phrase
d. M + BS
16. a. niraksharate mattu adara nivaarane
b. NP + Conj + [Pron + Gen] + NP
c. Coordinate and Genitive Phrase
d. BS + E
17. a. nuutana shikshana vidhaanagalu
b. Adj + NP + [NP + Pl]
c. Adjectival Phrase
d. T + BS
18. a. vyaasanga shikshaka
b. Atr + NP
c. Attributive Phrase
d. E + BS
19. a. pariikshegalu mattu maulyamaapana
b. [NP + Pl] + Conj + NP
c. Coordinate Phrase
d. P + E
20. a. praathamika shaalegalalli kannada
b. Atr + [NP + Pl + Loc] + NP
c. Attributive and Locative Phrase
d. P + P
21. a. saaksharige saahitya suutragalu
b. [NP + Dat] + Atr + [NP + Pl]
c. Dative and Attributive Phrase
d. P + IS(b) + BS
22. a. shaikshanika manoovignaana
b. Atr + NP
c. Attributive Phrase
d. BS + IS(a) + BS
23. a. shikshakarigaagi kaanuunu
b. NP + Purposive Part.+ NP
c. Purposive Participial Construction
d. BS + IS(a) + BS
24. a. suukshma boodhane
b. Atr + NP
c. Attributive Phrase
d. E
25. a. boodhanaaniyamagalu mattu shikshana samasyegalu
b. [NP + Pl] + Conj + Atr + NP
c. Coordinate and Attributive Phrase
d. E + BS + M
26. a. shikshanadalli sankhyaashaastra
b. [NP + Loc] + NP
c. Locative Phrase
d. BS + IS(a) + BS
27. a. raastriiya shikshana samasye
b. [NP + Gen] + Atr + NP
c. Genitive and attributive Phrase
d. S + BS + M
28. a. aacaraneyalli shaikshanika aadalita
b. [NP + Loc] + Atr + NP
c. Locative and Attributive Phrase
d. T + BS + E
29. a. shikshana mattu prajaasatte
b. NP + Conj + NP
c. Coordinate Phrase
d. BS + P
30. a. bhaaratadalli krushi shikshana
b. [NP + Loc] + Atr + NP
c. Locative and Attributive Phrase
d. S + BS + IS(a) + BS
31. a. vidyaabhyaasadalli kaleya sthaana
b. [NP + Loc] + [NP + Gen] + NP
c. Locative and Genitive Phrase
d. BS + IS(a) + BS
32. a. shikshanadalli taayinudigee agrasthaana
b. [NP + Loc] + [NP + Dat] + NP
c. Locative and Dative Phrase
d. BS + P
33. a. vidyeya pracaara
b. [NP + Gen] + NP
c. Genitive Phrase
d. BS + E
34. a. pracaaroopanyaasagalu mattu shikshana
b. [NP + Pl] + Conj + NP
c. Coordinate Phrase
d. E + BS
35. a. unnata shikshanadalli prakatanegala paatra
b. Atr + [NP + Loc] + [NP + Pl + Gen] + NP
c. Attr, Loc and Genitive Phrase
d. P + BS + E
36. a. bhaaratakkondu bahiranga vishvavidyaalaya
b. [NP + Dat + Numeral] + Atr + Np
c. Dative and Attributive Phrase
d. S + P
37. a. ahyaapakarige vruttishikshanada avashyakate
b. [NP + Pl + Dat] + Atr + [NP + Gen] + NP
c. Dat, Attr and Genitive Phrase
d. P + BS + M
38. a. pariikshegalalli sudhaarane
b. [NP + Pl + Loc] + NP
c. Locative Phrase
d. M + E
39. a. praathamika shikshanadalli agatya badalaavanegalu
b. Atr + [NP + Loc] + Atr + [NP + Pl]
c. Attributive and Locative Phrase
d. P + BS + E
40. a. shikshana - samskruti
b. NP + NP
c. Coordinate P
hrase d. BS + IS(a) + BS
41. a. vaiyaktika mattu saamuuhika boodhanaakrama
b. NP + Conj + Atr + NP
c. Coordinate and Attributive Phrase
d. M + IA(a) + M + E
42. a. shikshanadalli preerane mattu kalike
b. [NP + Loc] + NP + Conj + NP
c. Locative and Coordinate Phrase
d. BS + E
43. a. shaikshanika aadalita mattu pracalita samasyegalu
b. Atr + NP + Conj + Atr + [NP + Pl]
c. Attributive and Coordinate Phrase
d. BS + E + M
44. a. shikshana samsyegala aarthika vicaarane
b. Atr + [NP + Pl] + Atr + NP
c. Attributive Phrase
d. BS + M + P
45. a. shikshanadalli kraantkaari Ruuso
b. [NP + Loc] + Atr + NP
c. Locative and Attributive Phrase
d. BS + E
46. a. shikshanada taatvika mattu saamuuhika muulaadhaaragalu
b. [NP + Gen] + Atr + Conj + Atr + [NP + Pl]
c. Gen,Attr and Coordinate Phrase
d. BS + M + IA(a) + M
47. a. baala manoovignaana mattu shikshana
b. Atr + NP + Conj + NP
c. Attributive and Coordinate Phrase
d. P + BS + IS(a) + BS
48. a. shikshanadalli sankhyaashaastra
b. [NP + Loc] + NP
c. Locative Phrase
d. BS + IS(a) + BS
49. a. shikshanada saamaanya haaguu vishishta paddhatigalu
b. [NP + Gen] + Atr + Conj + Atr + [NP + Pl]
c. Gen,Attr and Coordinate Phrase
d. BS + M
50. a. shikshana ksheetradalli khaasagi samsthegalu
b. Atr + [NP + Loc] + Atr + [NP + Pl]
c. Attributive and Locative Phrase
d. BS + P
7.6 T G Rules to Kannada Expert System
The TG rules to expert system in Kannada are formulated on the basis of the analysis presented in 7.6.1 and 7.6.2.
7.6.1 Application of TG
As said earlier(7.0), by transformational rules, surface structure is got by deep structure where in semantic representations are seen clearly. In order to arrive at the deep structure of IL, following are the steps in developing parsers for the analysis of document titles in Kannada in the Knowledge representation model in PATR notation.
Step 1. Identification of syntactic categories
Step 2. Generation of syntactic structures
Step 3. Semantic interpretation of titles
Step 4. Identification of elementary categories
Step 5. Generation of subject entries
7.6.1.1 Step 1 - Identification of Syntactic Categories
Example: shikshanadalli manoovijnaana
Word Shikshanadalli:-
w: cat === n,
w: des === n + loc
w: sem === "shikshanadalli"
Word Manoovijnaana:-
w : cat === n,
w : des === n
w : sem === "manoovijnaana".
The parser makes use of the lexicon designed in the PATR notation as shown above. The PATR notation is slightly modified to include one more feature `word description', to account for morphological inflections. Also, semantic description of words is given in " " which supplies the input text to the parser. The parser checks each and every word of the title in the lexicon and displays the desired output identifying the syntactic category.
7.6.1.2 Step II - Generation of Syntactic Structure
The following are the rules to generate syntactic structure of document titles.
1. T → (XP) (NP) (CONJ.) (NP) NP
2. NP → (Atr.)*/(Adj.)* N/prn
Where T stands for Title
XP stands for Participle phrases of the following types:
1. Relative participle
2. Negative
3. Purposive
NP stands for Noun Phrase(with all possible combinations
of case and number suffixes).
Atr stands for Attribute
Adj stands for Adjective `*' notation indicates that it can
be repeated any number of times.
N stands for Noun
Prn stands for Pronoun
( ) indicates that it is optional.
The rule for attributes and adjectival phrases are recursive so that it can accept any number of them to be preceded before a noun. Hence the symbol `*' representing that the element can occur any number of times.
To generate syntactic structures of the above mentioned title, the parser has to make use of the rule stated above. Firstly, it identifies the individual words - "shikshanadalli" ; "manoovijnaana" with the help of second rule and builds up the higher structure NP NP referring into the first rule and finally in the output:
T → NP NP is generated which depicts the syntactic and morphological structures accordingly.
7.6.1.3 Step III- Semantic Interpretation of Titles
The NPs generated in step two undergoes semantic processing so that the coherency of titles is tested. In the above said example, it is semantically coherent. Semantic interpreter makes use of logical connections to account for compound words and thereby parsers the compound units as a single item. The space between two units would be discarded and the operator " ^ " is used to conjoin them.
Example: pariiksha^paddhati
shikshana^kshetra
shikshana^paddhati
boodhana^krama
7.6.1.4 STEP IV - Identification of Elementary Categories
The NPs thus generated by syntactic and semantic processing are sent to the lexicon to encounter the fact or features of each item stored. If the parser encounters a better usage it may be replaced accordingly.
Example ; "vidyabhyaasa" can be replaced by "shikshana."
It should be noted that the replacement does not effect semantic and syntactic categories of the word.
7.6.1.5 STEP V - Generation of Subject Entries
The strings identified by the parser after undergoing all the four steps mentioned above, are sorted.
The sorted list with all the categorical markers will be displayed in the form of a tree structure.
Example: shikshanadalli manoovijnaana
T → NP NP
Syntactic tree:
[ (shikshanadalli)NP1 (manoovijnaana)NP2 ]
Morphological representation
[(NP1 (shikshana)N (alli) loc (NP2(manoovijnaana)))]
Basic requirement in this system is building the lexicon with syntactic features explained against each word.
7.7 Classificatory Structure Based on CC
The last columns of 7.6.1 and 7.6.2 present the classificatory structure according to CC Fundamental Categories(FC). While analyzing the titles, structure words such as conjunctions, pronouns, etc., are deleted and only concepts concerned with the discipline are taken into account. As done in the case of NL analysis the terms are tagged with the FCs and Basic Subject in the same order of the concepts rendered in the title.
The IL structure as per SRR's analytico synthetic school of thought is,
BS,P;M:E"ACI.S`T
where BS is the basic subject and it is the default in IL representation. As said in 3.2, PMEST are the FC and ACI is the anteriorising common isolate. This is the transformational rule from which NL representation is converted to IL representation. The faceted IL representation helps in juxtapositioning the concepts thereby, facilitates browsing. This can be stated as a special performance of IL because, the same cannot be performed by NL representation.
While transforming the NL to IL following are the criteria involved: (a) The FC Personality is equivalent to thing/object , (b) The FC Matter is equivalent to property, (c) the FC Energy is equivalent to action/work in NL representation. The PMEST structure has revealed a modulated formulation of decreasing concreteness. Citation order is helpful in defining the subject. Since PMEST is the defined facet structure for IL, it is not necessary to formulate any new facet rules . As regards the `Basic Subject'(BS), in this case default will be `shikshana' `Education'. In one of the earlier studies done on the `Statistical model for IL in Kannada' (Sharada 1994), it was found that 85% of the titles rendered the B S in first and second place of the titles, allowing to conclude that, the document titles reflect the discipline to which they belong to, as against the findings of Brooks (1968) study done on the `Stability of keywords in text of radiological reports,that offered an inefficient and precarious basis for indexing retrieval system.' As per the observations made on 7.6.1 and 2 , 60% and 70% respectively have the B S `shikshana' `Education' in its titles. The difference of 10% may be due to spontaneous rendering of titles by experts without writing the document. But it is also observed that, in both the lists, it is not difficult to identify the BS from the titles, because related words to the discipline such as, `boodhane' `teaching'; `vidyabhyaasa' `education'; `shaale' `school' etc., are used in rendering the titles. Hence in the present experiment BS can be easily identified and `shikshana' `education' will be default to all the titles as BS in the IL analysis irrespective of the term `shikshana' rendered in the title.
7.8 Conclusion
Automatic indexing may take some more time until NLP research offers definite results. Some models are successful in generating subject strings from titles presented in NL.
The NLP approach in information retrieval is a developing phenomena. As for as Kannada is concerned, word processors so far developed in Kannada are not compatible to work in NLP environment.
As regards IL structure, PMEST facet structure is very near to NL structure of Kannada and other Dravidian languages as revealed in 3.4 ( Table-2 ) having SOV word order. Hence it is not necessary to formulate any new IL rules in order to analyze the titles.
*** *** ***
CHAPTER EIGHT
ILLUSTRATIVE EXAMPLES IN DEMONSTRATING RULES
| 8.0 | Introduction |
| 8.1 | Sample Data |
| 8.2 | Models |
| 8.2.1 | Authority List |
| 8.2.2 | Subject - Chain Based Indexing |
| 8.2.2.1 | Case Representation |
| 8.2.2.2 | Term Representation |
| 8.2.2.3 | Language |
| 8.2.2.4 | Notation |
| 8.2.2.5 | Schedule Preparation |
| 8.2.3 | Title - Key Word Indexin |
| 8.2.3.1 | Comparative Study |
| 8.3 | Conclusion |
8.0 Introduction
An attempt is made in this chapter to apply the theories elucidated and rules formulated in the previous chapters and device a sample Classification Schedule in Kannada taking one discipline as an example. The discipline chosen here for demonstration purpose is siksana 'Education'.Devices mentioned in 6.2.1, the proceedures for development of SH such as vocabulary control,word combinations,spellings,etc. and other related topics mentioned under the same chapter heading are taken into consideration
8.1 Sample Data
As mentioned under 6.3 the selection of descriptors,in order to collect the terms the present study depended on two sources. They are:
- Published documents
- Cognitive paradigm
Published documents
Listed below are the documents referred to collect the terms:
- paaribhaasika padakoosa: Saarvajanika siksana ilaakhe.Bangalore, Department of Kannada and culture. 1988
- Virappa, N.S. siksanasaastrada paaribhaasika nighantu. Mysore,Kannada Adhyayana Samsthe. 1981.
- 'granthaloka' a monthly journal in Kannada (Entries are classified in this journal. Titles pertaining to the discipline siksana were collected)
Cognitive Paradigm
This was accomplished by administering the keywords among ten experts in 'Education'(for detailed discussion refer to 7.4). Though the same set of terms were distributed to all the ten experts each one of them derived different set of titles reflecting individual ways of thinking in deriving the titles. These set of titles also helped in updating the words existing in the glossary and replace them with the concepts in currency.
8.2 Models
8.2.1 Authority List
Authority list such as Sears List of Subject Heading, LCSH, etc.,are in English and similar lists are not yet produced in Kannada.
8.2.2 Subject - Chain Based Indexing
As said in 6.5.2, subject chain based indexing is quite appropriate for the purpose of deriving subject headings and pre - coordinate indexing, SRR's Colon Classification has been adopted since the facet syntax of CC tallies with the word order of Kannada (refer 3.4). Even the rules part has been followed as in CC . In addition to the rules and principles mentioned in 6.2.1.1, the following grammatical aspects are also taken into consideration.
8.2.2.1 Case Representation
The terms are represented in nominative case. In Kannada, the basic form of the noun as it occurs as either the subject or predicate nominal in a sentence phrase is the nominative case. Also nominal base with its gender number marker itself is used in the nominative. It is in this basic form that a Kannada noun is listed in the dictionary.
8.2.2.2 Term Representation
As far as possible, single term representation has been used. Compound terms are also used in some cases and also by reversing the natural language order - For example if noun precedes the Adjective. For example : patthyeetara catuvatike 'extra curricular activities.'
8.2.2.3 Language
If equivalent terms are not found in Kannada, and if the borrowed term has the currency, instead of translating, the terms are retained as they are much familiar to the user. For example: doctorate padavi which represents English and Kannada terms 'Doctorate Degree'.
8.2.2.4. Notation
Notation adopted for the present study is the same as in CC 7th edition . Additions could be made within facets. CC notation or notational plane includeds:
alphabets both Roman small and capital excluding: i,l,and o,
number Indo Arabic numeral from 0 to 9,
Greek letter D delta
ordinary indicator such as:
( ) arrester bracket
& ampersand,
' single inverted comma
" double inverted comma
, comma
- hyphen
= equal to
. dot
: colon
; semicolon
→ forward arrow
←backward arrow
The notational system of CC is a mixed one and the total number of digits are 74.
8.2.2.5 Schedule Preparation
For the purpose of demonstration, discipline 'Education' has been selected. Appendix 5 presents the schedule part. Appendix 6 presents the list of subject headings arranged alphabetically along with the notation and FC within parenthesis.While preparing the list , though done manually, the principle of context dependency was kept in mind in order to generate sensible index entries.
Passive construction adopted by PRECIS seemed better to be followed. But in Kannada, the passive is infrequently used in the written and formal spoken variety. Because, the agent nominal of the passive is in the instrumental case. The underlying direct object becomes the derived subject and receives nominative marking and governs verb agreement. Then underlying subject becomes an oblique object and receives the instrumental marking. The verb is converted into an infinitive and the auxiliary padu is inserted to its right. It sounds artificial and pedantic to native ears. It is restricted mostly to 'formal' registers, such as text books, government notification and newspaper reporting and advertising copy translated from English or Hindi (Sridhar 1990).
ii pustakavu mantrigalinda bidugade maadalpattitu.
'This book has been released by the Minister.'
And also this type of usage is not in practice in representing document titles. Using Nominative case in term representation, maintains the uniformity. If the same methodology is applied to other disciplines, we may get productive results.
8.2.3 Title - Keyword Indexing
Appendix - 8 gives a picture of how KWIC works in Kannada. Fifty titles in Kannada on the discipline Education has been selected for analysis. The titles were fed to the computer using 'Bhasha' word processor developed by the Central Institute of Indian Languages, Mysore. 'Kavita' software was used for indexing purpose. Appendix 8 and 9 present both KWIC and KWOC using these fifty titles. In order to do the comparative study of Chain procedure and Keyword Indexing, the fifty titles were manually analyzed based on the schedule prepared in Kannada on Education. Appendix 7 presents the same.
8.2.3.1 Comparative Study
Subject chain is clusterally and ordinally good. But while communicating, naturalness will be absent since there is no inflections and structure words. The KWIC and KWOC provides content in NL, which is highly communicable for a searcher in a subject field. Each term is given importance with the result, each word provides access point in the title in which it occurs and will act as whole context specifier.In case of subject chain, the string is organized in a logical structure in a host subject - first concept being the subject representation, second and its subsequent concepts will be the manifestation of the fundamental categories ie., PMEST. Forwarding techniques chosen for this purpose are helpful in finding cohesive clusters of subject , based on inclusive relationship. The only disadvantage is , subject chain is not inter linked as auxiliary terms or inflections are not there to make it more easier for the searcher.
8.3 Conclusion
It may be concluded here that chain procedure to prepare the pre coordinate IL in Kannada is quite ideal. As we are seeing the development in computer applications in Kannada , it is possible to retrieve the needed information in NL using KWIC & KWOC.
*** *** ***
CHAPTER NINE
CONCLUSION
| 9.0 | Introduction |
| 9.1 | IL and Linguistics |
| 9.2 | Structure and Vocabulary of IL |
| 9.3 | Word Order of NL and IL Structure |
| 9.4 | Kannada Monolingual Glossary |
| 9.5 | List of Main Subjects |
| 9.6 | PCIL in Kannada |
| 9.7 | NL Approach to IL |
9.0 Introduction
The present study investigated two dimensions of an IL: (a). Pre- coordinate Indexing Language (PCIL) and (b). NL approach. The first one is the artificial, technical language consisting of descriptors using controlled vocabulary and ordinal numbers for the systematic arrangement of books in the library. It is designed for mechanically shelving innumerable books in a predetermined helpful sequence. The paucity of such a scheme of PCIL in Indian languages, identifies the need to develop a module based on the grammatical characteristics of a language. In the present information era, it is well known that knowledge is growing very fast and it is infinite. The PCIL should be designed in such a way to cater and manage the old, retrospective and future knowledge, securing exact position among the already existing ones. This is possible if the provision is made in the construction of descriptors and a flexible notational system. Notation such as: octave, decimal fraction, zone and sector; digits such as: empty and emptying; devices such as: subject, alphabetical and mnemonic, and phase relation are some of the components of a freely faceted analytico synthetic classificatory system. All these components are provided and applied in Colon Classification which is the best example for a PCIL.. Hence in the present study, CC is used as the basis in preparing the PCIL module in Indian language.
The limitations of the study are :(a) Restricted to one Indian language, Kannada. As said in 4.2, it is one of the modern Indian languages included in the VIII Schedule of the Constitution of India. The development of technical literature and education in all spheres of life in Kannada, confirms the need to develop an IL in Kannada. (b) The discipline 'Education' is selected for experiments in both the above mentioned dimensions of IL. The reason for selecting 'Education' is that, if the discipline Information Science monitors and manages the universe of knowledge, the discipline 'Education' has theories and techniques to teach the universe of knowledge. (c). Chomskian transformational grammar among natural language grammars and Ranganathan's Colon Classification are used in designing the IL module in Kannada in both the dimentions taking into account the flexible properties of both as explained in chapters 2 and 3 (3.1 to 3.4) respectively.
9.1 IL and Linguistics
The hypothesis that the concepts of IL can be analyzed in a proper viewpoint with the knowledge of linguistics is demonstrated in both the above said IL dimensions. Hence, in the process of matching the formal and informal states of mind (Figure 1),an interdisciplinary perspective 'Infolinguistics'(1.1.1) is introduced wherein linguistics is used as a representation mechanism in analyzing the text of the document. Also in the process of developing the vocabulary of a PCIL, the important attributes of NL to be taken into consideration are, its phonology, orthography, lexicon, morphological features such as different verities of nouns like, simple, derived, compound, etc., gender, number, adjectives, attribute, semantics and case grammar. With reference to the NL approach of IL, if the classificatory language facilitates collocation and browsing, the NL approach helps the user to interpret the subject of the document accurately as discussed in 3.4. For this purpose, the present study depended on TG. The rules derived in TG are tested in general on IL. In a personal discussion, K.V.Thirumalesh of CIEFL, Hyderabad, an expert in TG and working on Kannada, said that, the theories of TG applicable to IL can be applied to Kannada also, since case morphology system is richer in Kannada. Hence the theories from TG such as, X - Bar convention, Case theory and q theory demonstrated for IL in 3.6.2 .1 to 3.6.2.3 can be applied to IL in Kannada also.
9.2 Structure and Vocabulary of IL
The hypothesis that, any language, whether it is natural or artificial has its structure and vocabulary is proved by revealing the structure and vocabulary of IL. Like NL, IL has phonemes, parts of speech and dictionary by which it tries to overcome ambiguous expression. The phoneme of IL are the ordinal numbers in case of notational representation or descriptors in case of verbal representation. Parts of speech of IL are the fundamental categories and connectives. Grammar of IL is in the form of postulates and principles by which these ordinal numbers or descriptors are combined in order to translate the specific subjects to class representation. This, on the whole, comprises the structure of IL. As explained in Table 3, the vocabulary/lexicon of IL is taxonomic/thesaurus based. The synthetic process of IL are free from homonyms and synonyms.(Agarwal and Sharma 1994).
9.3 Word Order of NL and IL Structure
Facet structure of a subject proposition can be correlated to similar structure in linguistics. Keeping this factor in view, an IL model derived for Kannada are applicable to the Dravidian languages in particular and all the Indian languages in general because, India is a geographical region determined by shared linguistic characteristics. Also, most of the Indian languages have Subject Object Verb (SOV) word order, that is similar to the facet syntax (PMEST) proposed by S R Ranganathan in CC. This is demonstrated in the comparative study of syntactic structure of document titles in English, Kannada, Tamil, and Telugu and facet structure of IL (Table 2). As discussed in 3.4, the facet structure (PMEST), is very near to word order of Indian languages. Hence it is quite relevant to adopt CC proposed by SRR as a system for developing the PCIL for Indian languages.
9.4 Kannada Monolingual Glossary
In the process of developing an IL module in Kannada, first preference is given to the lexicon. Based on the principles used in developing glossaries(5.3), linguistic principles in which a glossary can be prepared scientifically(5.3.1.4) and standardization of technical terms as explained in 5.2, a monolingual Kannada technical glossary in 'Education' is prepared using the word frequency count(5.3.1). By using this glossary, controlled vocabulary can be achieved. In this glossary, the terms are in such form of entry similar to a dictionary, with each word represented in nominative case, without any syntactic markers, in singular, etc. In the absence of a list of subject headings in Kannada, the glossary serves the purpose and it is presented in Appendix - 1.
9.5 List of Main Subjects
Based on the principles adopted in CC for the arrangement of main subjects, a list of traditional main subjects in Kannada is presented in Appendix - 2.
9.6 PCIL in Kannada
Appendix - 5 is a PCIL example in Kannada for the discipline 'Education'. The descriptors are so designed keeping in view the following points:
- The properties of Kannada in concept representation as discussed in 4.4 to 4.7,
- the Kannada Style Manual rules for term representation and spelling,
- rules that are borrowed from the existing PCILs suitable to Kannada language,
- procedures for development of SH explained in 6.2.1 to 6.2.1.2,
- the ISO 2788 the standard to develop thesaurus and
- the process of selection of descriptors as discussed in 6.3, etc.
Regarding the collection side published titles listed in 8.1 are searched. Regarding the users side ,especially to demonstrate brain storming among experts(6.3), an experiment was carried out by selecting ten experts in the field of Education. This experiment showed how experts derive titles at the cognitive level spontaneously even without writing a document . In order to enable them to derive at titles, the keywords(Appendix 4) extracted from published titles(Appendix 3), were administered. In total 100 titles were derived by the experts without any repetition or similarity and also, this reflected the latest trend in the usage of technical terms in the discipline. This helped in updating the descriptors. For example, the term vidyaabhyaasa was replaced by the term siksana, suuksma boodhane was replaced by anuboodhane and the former got the 'see' entry in the Index of Subject Headings with notations (Appendix 6) appended to the schedule.
9.7 NL Approach to IL
For the NL approach of IL, it is recommended to tackle the problem using computers. In order to derive rules in the NLP environment for IL in Kannada, the hundred titles derived from the experts in the above said experiment, which represented the user's side and fifty published titles from the collection side were used for syntactic analysis. While deriving rules for developing Parsers for IL in Kannada, this experiment gave full support to the statement that, it is sufficient to recognize the NPs in the IL environment, because, most of the document titles are not complete sentences. In the titles, instead of a verb, a noun variant of a verb is present. For analyzing the sentence in NL, the parsers are already developed based on Chomskian transformational grammar. In the present study it is inferred that instead of following the NLP structure, depending upon the objective of the study and the problems to be tackled, rules can be formulated. Based on the TG model, after analyzing in total 150 documents in Kannada, parsers for IL in Kannada are developed. Though the rules are derived for the knowledge representation model in Kannada, it may take some more time until NLP research offers definite results. More over, the available word processors in Kannada are not compatible to work in the NLP environment. Transliteration in Roman script can be adopted using the standard Kannada transliteration chart (Upadhyaya 1972).In order to manage and process the IL in the NL environment and retrieve the needed information, automated indexing is much helpful. This also works in the computer environment. Using the relevant Kannada word processor and indexing software, KWIC and KWOC are achieved. The same are presented in Appendix - 8 and Appendix - 9. Also, micro CDS/ISIS along with Kannada in the GIST card in the hard disk, enables to create information storage and retrieval system with powerful search facility. The inverted file facility of CDS\ISIS creates index in Kannada alphabetical order.
The comparative study of chain procedure and automated index such as KWIC and KWOC in Kannada, infers that, the chain procedure is ideal to prepare PCIL and for the information retrieval, automatic indexing such as KWIC, KWOC, Micro CDS/ISIS (with Kannada GIST card) are suggested. The structure of subject chain is presented in Appendix - 7.
On the whole, the methodology to prepare the modules of attributes of IL are discussed and sample modules such as, Technical Glossary in Kannada, list of Main Subjects, Classification Schedule along with an index of descriptors with notation, TG rules to analyze Kannada titles in the NLP environment, KWIC and KWOC indexes are presented. Since India is a linguistic area, the rules proposed in the present study in preparing the IL modules could be applied to other Indian languages and the gap left in the paucity of research in developing IL in Indian languages may be filled. The present study acts as a step forward in developing IL in Indian languages.
On the whole, this thesis has investigated the problems of indexing technical literature in Kannada language. For this purpose syntactic procedures of the NL has been used. The transformational grammar provides a systematic approach to identify syntactic structures of an NL which are having semantic connotations. Thus we are going to find an IL structure identical with TG. On the whole the thesis provides an analytico synthetic approach to an IL. It provides a procedure for indexing technical literature in Kannada. Further thesis identified method for generating classification schedule and glossaries helpful as supporting tools for indexing.
*** *** ***
REFERENCES
Allan, Keith. (1992). Semantics: An over view. In William Bright (Ed.), International Encyclopedia of Linguistics, (pp.394-399), New York,Oxford University Press.
Anna-Maria di Sciullo, & Williams,Edwin. (1987). On the definition of word. Cambridge,MIT Press.
Austin, Derek . (1987). PRECIS. In Alan Kent & Harold Lancaster (Eds.), Encyclopedia of library and information science, Vol.42 supplement 7, (pp.375-422). New York, Marcel Dekker.
Bangalore University permits writing theses in Kannada. The Hindu,28.8.1990.
Bhat, D.N.S. (1991). An introduction to Indian grammars. Part 3 - Adjectives. A Report submitted to the University Grants Commission.
Bhattacharya,G. (1972). General theory of library classification and classifying according to UDC. Library Science, 9(2),197-228.
Bhattacharya,G.(1979). Postulate based permuted subject indexing system. Library Science, 16, Paper A.
Bhattacharya,G & Neelameghan,A. (1969). Postulate based subject indexing for dictionary catalogue system. Bangalore, DRTC Annual conference, Paper A.
Bierwisch,M. (1970). Semantics. In John Lyons (Ed.) New horizons in linguistics. London, Penguin.
Biligiri,H.S. (1969). Kannada . In Thomas A Sebeok (Ed.), Current trends in linguistics, Vol 5 - Linguistics in South Asia (pp.394-410), The Hague, Mouton.
Borko,H. (1965). Research on computer based classification systems. Proceedings of the second international study conference, Elsimore,(pp220-38).
Borko, H. & Bernier,C.L.(1978). Indexing concepts and methods. New York, Academic Press.
Bornstein, Diane D. (1977). An introduction to transformational grammar. Cambridge, Winthrop.
Bratko, Ivan.(1986). PROLOG programming for artificial intelligence. Werkingham, Addison-Wesley.
Brooks,B.C. (1968). The stability of ranks of index terms. American Documentation, 19(1),101-102.
Brown, A.G. (1970). Chain indexing : An introduction to subject indexing. In Alan Kent & Harold Lancaster (Eds.), Encyclopedia of library and Information science(pp.275) New York, Marcel Dekker.
Chase,Stuart. (1937). The tyranny of words. New York, Harcourt Brace.
Chidanandamuurty,M. (1984). Kannada. In K.M.George (Ed.) Comparative Indian literature, Vol 1.(pp. 19-21). Trichur & Madras, Kerala Sahitya Academy & Macmillan.
Chomsky, Noam. (1965). Aspects of the theory of syntax. Cambridge, MIT.
Chomsky, Noam. (1975). Syntactic structures. The Hague, Mouton.
Chomsky, Noam. (1975). Reflections on language. New York, Pantheon Books.
Chomsky, Noam. (1977). Language and responsibility. New York, Pantheon Books.
Chomsky,Noam. (1986). Barriers.(Linguistic Inquiry Monograph 13). Cambridge, MIT.
Chomsky, Noam. (1981). Lectures on government and binding. Foris, Dordrecht.
Chomsky,Noam. (1991). Linguistics and cognitive science: problems and mysteries. In Asa Kasher (Ed.) The Chomskian Turn. (pp.26-53). Cambridge, Basil Blackwell.
Chomsky,Noam. (1991). Linguistics and Adjacent fields: A personal View. In Asa Kasher (Ed.) The Chomskian Turn. (pp.3-25) Cambridge, Basil Blackwell.
Chomsky,Noam. (1992). A minimalist program for linguistic theory. (MIT occasional papers in linguistics. Number 1)
Clarke, A.L. (1933). Manual of Practical indexing. London, Grafton.
Collison, Rober.L. (1959). Indexes and indexing. London, Ernest Benn.
Devadason, F.J. & Kumbhar, M.R. (1988), 35(2). Language and indexing language: Nalimov and Gardin revised. Annals of library science and documentation, 35(2) pp.58-68.
Firth, J.R. Proceedings of the Seventh International Congress of Linguistics.
Foskett, A.C. (1981). The subject approach to information. 4th ed. London and Hamden, Clive Bingley and Linnet books.
Friedman, Joyce, et al. (1971) A computer model of transformational grammar. New York, American Elsevier.
Friedman, Joyce. (1971). A computer model of transformational grammar. New York, Elsevier.
Gao, Chong Quin & Guo, Hua. (1987). Complication of "Subject Term list in Chinese words" [in Japanese] Johokauri, 30(2) pp.106-115.
Gopinath,M.A. (1992). Descriptors and their role in information retrieval , Bangalore, DRTC workshop on information retrieval.
Gopinath,M.A. (1994). Indexing language : Its structure and development. In M. A. Gopinath (Ed.) Teaching research and practice in classification and indexing languages,(pp 45 -70). Bangalore, DRTC.
Gopinath,M.A. (1994). Research in classification: A pointer towards knowledge representation . In M.A.Gopinath (Ed.) Teaching research and practice in classification and indexing languages,(pp.1-11). Bangalore, DRTC.
Grierson, G.A. (1967). Kanarese. In G.A.Grierson (Ed.) Linguistic Survey of India. Vol 4. Delhi, Motilal Banarasidass. (pp.362-405).
Grinder,John T & Elgin,S.H. (1973). Guide to transformational grammar: History,theory, practice. New York, Holt,Rinehart & Winston.
Hanasoge, J. M. (1974). Kannada samaanaarta koosha. Mysore, Nabashree.
Harris, Kevin. (1986). Controlled vocabulary for literature studies. International Classification,13(3),133-136.
Havanur, Srinivasa. (1974). Hosagannadada arunoodaya. Mysore, University of Mysore.
Hemalatha Iyer. (1983). Structure of indexing languages and retrieval effectiveness. University of Mysore, Ph.D Dissertation.
Hemalatha Iyer. (1990). Natural language representation: Transformational rules. International Classification, 17(1), pp.8-13.
Heny,F. (1981). Binding and filtering. Cambridge, MIT.
Hockett,C. F. (1942). A system of descriptive phonology. Language, 18, pp3-21.
Immorth,John Phillip. (1979). A lexical essay towards the development of the theory of indexes to classification schemes. In A. Neelameghan (Ed.) Ordering systems for global information network (pp.136-41), Bangalore, FID/CR Committee and Sarada Ranganathan endowment for library Science.
India,Government of. (1987). Report : Review committee on the scheme of university level book production in Indian languages. Delhi, Ministry of Human resource development.
Jabrzemska, E.S. (1987). Survey of indexing languages used in Polish information establishments. International forum on information and documentation,1(2), pp.12-13.
Jackendoff,R. (1977). X Syntax: A study of phrase structure. (Linguistic Inquiry Monograph 2). Cambridge, MIT.
Jacobson,B. (1986). Modern transformational grammar. New York, North Holland.
Johansen, Thomas. (1990). Methods of subject structure display. International Classification, 17(1), pp. 2-7.
Jones, Karen Spark & Kay,Martin. (1973). Linguistics and information science. New York & London, Academic Press.
Kannada abhivrudhi: Parishrama pragati. (1988). Bangalore, Directorate of Kannada and culture.
Kannada sahitya parishad. (1977). Kannadada sarvangiina pragati: Ondu brihad yojane - Blue print. Bangalore, Kannada sahitya parishat.
Kannada shailikaipidi. (1995). Hampi and Mysore, Kannada University & Central Institute of Indian Languages.
Karnataka, Government of. Bhashantara nirdeshanaalayada kaarya chatuvatikegalu. Bangalore, Bhashantara nirdeshanalaya.
Katz, Jerrold J. (1980). Chomsky on meaning. Language, 36(1),pp. 1-41.
Katz, Jerrold J. & Fodor,Jerry .A. (1963). The structure of a semantic theory. Language, 39, pp.170-210.
Kedilaya, A. Shankar.(1970). Foreign loan words in Kannada. Madras, Madras University.
Kempegowda, K. 1976. Bhashavijnaana koosha. Mysore, Institute of Kannada Studies.
Kiefer, Ference. (1992). Case. In William Bright (Ed.) International encyclopedia of linguistics, Vol. 1 (pp.217-218), Oxford, Oxford University Press.
Krishnabhat, A. (1985). Vijnana baraha mathu Kannada. In L.S. Sheshagiri Rao (Ed.) Kannadada alivu ulivu (pp253-259), Bangalore, Kannada Bhaasha Abhivruddiya Samiiksha Prakashana.
Kyle, Barbara. (1958). Towards a classification for social literature. American Documentation, 9, pp.168-83.
Lancaster,F.W. (1979). Information retrieval systems. New York, Wiley.
Leech, Geofrey. (1975). Semantics. Middlesex, Penguin.
Macdonald, R.R. (1965). Linguistic structure. In S.M. Newman (Ed.)Information system compatibility. Spartman, Macmillan.
Mallikarjun, B. (1985 ) . Vocabulary education. Mysore, Vaagdevi Pustakagalu.
Marantz, Aled. (1984). On the nature of grammatical relations. Cambridge, MIT Press. (Linguistic Inquiry monograph 10).
McCormack, William & Krishnamurthi, M.G. (1966). Kannada. Maclison, University of Wisconsin.
McNeill, D. (1969). Empiricist and nativist theories of language: George Berkley and Samuel Bailey in the 20th century. In A. Koestler & J.R. Smythies(Eds) Beyond reductionism. (pp. 291)
Moers,C.N.(1963). Indexing language of an information retrieval system. Paper presented at an Institute conducted by the library school and the centre for continuous study. University of Minnesota, September 19-12. (pp.21-36.)
Nayak, H.M.(1967). Kannada: literary and colloquial. Mysore, Rao and Raghvan.
Neelameghan,A. (1968). Classification , theory of. In Encyclopedia of library and information Science, Vol 5, (pp 147-74).
Neelameghan,A. (1972). Systems approach in the study of the universe of subjects. Library Science, 9(4), 445-472.
Neelameghan, A . (1971). Sequence of component ideas in a subject. Library Science, 8(4), 322-324.
Neelameghan , A. (1979). Absolute syntax and structure of an indexing and switching language. In A.Neelameghan (Ed.) Ordering systems for global information networks (pp. 165-177) Bangalore, FID/CR & Sarada Ranganathan endowment for library science.
Neelameghan, A. & Gopinath, M.A.(1972). Fused main subjects. Library Science, 9(3), 316-335.
Newmeyer, F.J. (1991). Rule and principles in the historical development of generative syntax. In Asa Kasher(Ed.) The Chomskian Turn, (pp 200-230). Cambridge, Basil Blackwell.
Ogden, C.K. & Richards, I.A. (1946). The meaning of meanings. London, Routledge.
Palmer,B.I. & Austin,D. (1971). Grammar. Middlesex,Penguin.
Parimalabai, N.B. (1965). Kannada bhasheya sankshipta parichaya . In L.S. Sheshagiri Rao (Ed.) Kannadada alivu ulivu,(pp. 1-24). Bangalore, Kannada bhasha abhivruddhiya prakashana.
Prasad, A.R.D. & Thakur, R.R.(1994). Natural language processing techniques in keyword identification from book titles. In M.A.Gopinath (Ed.) Teaching research and practice in classification and indexing languages, (pp.77-89). Bangalore, DRTC.
Prasad, A.R.D.(1993). Application of computer based natural language processing tools and techniques in developing subject indexing languages. Ph.D. dissertation. Dharwar, Karnatak university.
Prasher, A.G. (1989). Index and indexing system. New Delhi, Medllim press.
Radhakrisnan, S. (1983). Noun phrase in Tamil. Annamalai University Ph.D dissertation.
Raghavan, K.S. (1984). Postulate - based permuted subject indexing: A study of its effectiveness. University of Mysore, Ph.D. dissertation.
Rajan,T.N. (1981). Indexing systems: Concepts and techniques. Calcutta, IASLIC.
Ramaswamy,K.(1988). A contrastive analysis of the relative clauses in Tamil and English. Annamalai University Ph.D. dissertation.
Ramsden, Michael J. (1974). An introduction to index language construction: A programmed text. London, Clive Bingley.
Ranganathan, S.R. (1957). Prologmena to library classification. 2nd ed. Bombay, Asia Publishing House.
Ranganathan, S.R. (1962). Elements of library classification. 3rd ed. Bombay, Asia Publishing House.
Ranganathan, S.R.(1964). Subject heading and facet analysis. Journal of Documentation , 20, 109-19.
Ranganathan, S.R. (1967). Hidden roots of classification. Information storage and retrieval, 3 (section 7).
Reimesdijk, H Van & Williams, E.(1986). Introduction to the theory of grammar. Cambridge, MIT Press.
Riggs, Fred, W. (1991). Delphic language: A problem for authors and indexers. Library Science, 28(1), 18-30.
Robin, R.H. (1971). General linguistics: An introductory survey. 2nd ed. London, Longman.
Salton,G. (1989). Automatic text processing. Addison Wesley.
Schiffman, Harold F. (1992). Kannada. In International encyclopedia of linguistics (pp266-267). New York, Oxford.
Seetharamaiah, M.V. (1975). Shastra sahitya. Vol III. Bangalore, Bangalore University.
Seshagiri Rao, L.S.(ed) (1985) Kannadada alivu ulivu. Bangalore, Kannada Bhasha Abhivruddhiya Prakashana.
Sharada, B.A. (1985). Citation anaylis of the journal Indian linguistics 1971 - 1980.Indian Linguistics, 46 (3-4), 29 -45
Sharada, B.A. (1989). Research in Dravidian linguistics: A quantitative analysis. International Journal of Dravidian Linguistics, XVIII (1), 111- 123.
Sharada, B.A. (1990). Contribution to journal articles by Indian linguistics at the international scene. (with Devaki L). Annals of library science and documentation, 37 (1),35-52.
Sharada, B.A. (1993). A study of bibliographic coupling in linguistic research. Annals of Library Science and Documentation, 40(4), 125-137.
Sharada, B.A. (1994). Index language in Kannada : An experimental study. In M.A.Gopinath (Ed.) Teaching research and practice in classification and Indexing languages, (pp.91-101). Bangalore, DRTC.
Sharada, B.A. (1994). Statistical model for the distribution of index terms in Indian languages. Paper presented at National conference on bibliometrics, informetrics and scientometrics. Bangalore, LIBCON.
Sharada, B.A. (1994). Word count in Computational linguistics. Science and Science of Science, 3(5), 161-164.
Sharada, B.A. (1995). Infolinguistics: An interdisciplinary study. Library Science, 32 (3), 113-121
Sharada, B.A. (1995). Infolinguistics: A linguistic perspective. South Asian Language Review, V (2),100-110
Sharada, B.A. (1996). Informatrics and subject indexing language. Accepted for publication in IASLIC Bulletin.
Shivappa, D.S. (1973). English - Kannada vaidya pada koosha. Mysore, Sudhiir Prakaashana.
Singh, R.A. (1982) An introduction to lexicography. Mysore, Central Institute of Indian Languages.
Soergel, Dagobert. (1985). Organising information: Principles of data base and retrieval systems. New York, Academic Press.
Sridhar, S.N. (1990). Kannada. London , Routledge.
Sridhar, S.N. (1992). Language modernization: Structural and sociolinguistic aspects. South Asian Language Review, 2(1),84-101.
Ullman, Stephen. (1972). Semantics: An introduction to the science of meaning. Oxford, Basil Blackwell.
Venkatachala Sastri, T.V. (1985). Shikshana rangadalli Kannada. In L.S.Seshagiri Rao (Ed.) Kannadada alivu ulivu (pp.144-155 ). Bangalore, Kannada Bhasha Abhivruddhiya Prakashana.
Vignaana saahitya nirmaana. (1971). Mysore, University of Mysore.
Weinberg, Bella Hass(Ed). (1989). Indexing - the state of the art and the state of our ignorance. Medford, Learned Inform.
Whitney, William Dwight. (1975). The life and growth of language: An outline of linguistic science.
Wingrad, T. (1972). Understanding natural language. New York, Academic Press.
Wittgenstein, L. (1953). Philosophical investigation. Oxford, Blackwell.
*** *** ***
HOME PAGE | Headlines in Indian Vernacular Newspapers - Stylistic Implications | Children's Dictionary in Indian Languages | Preliminaries to the Preparation of a Wordnet for Tamil | Language: Pride, Prejudice, and Inferiority Complex - A Panoramic View | Language News This Month - N. T. Rama Rao and His Legacy | A Multilingual Approach Towards Language Teaching in Indian Schools | CONTACT EDITOR
B. A. Sharada, Ph.D.
Sourthern Regional Langauge Centre
Manasagangotri
Mysore 570006, India
E-mail: drsharada@sancharnet.in or sharada@ciil.stpmy.soft.net.